Note
Click here to download the full example code
Fetching the HBN example dataset¶
This example demonstrates how to use bids_bep16_conv.datasets to fetch
the HBN example dataset.
Much of the functionality of the bids_bep16_conv toolbox relies on downloading
candidate example datasets. Each dataset has its own functions to check and evaluate QC
files to find suitable participants, as well as dedicated download functions that will obtain
the data from the BIDS connectivity OSF project. The respective files differ between example datasets
and respectively utilized pipeline/workflow but are obtained in a way that they confirm
to BIDS common derivatives, specifically as input for tools that generate BEP16-related output.
Here we show how the HBN example dataset was generated and can be assessed, via describing the respective
workflow and utilized functions.
The HBN dataset and its derivatives are provided openly via the
FCP-INDI AWS bucket, entailing various
pipeline/workflow outputs. Here, we are going to focus on the preprocessing conducted via QSIprep.
At first, we need to find a suitable participant, in terms of overall data quality, Luckily, QSIprep
provides a respective file that includes a quality control score for each participant.
Using the datasets.get_HBN_qc() function we can obtain and check this file:
from bids_bep16_conv import datasets
HBN_qc_file = datasets.get_HBN_qc(return_df=True)
print(HBN_qc_file)
Data will be downloaded to bids_bep16_datasets/HBN/source-HBN_desc-qsiprep_participants.tsv
0%| | 0/210607 [00:00<?, ?it/s]
31%|###1 | 64.0k/206k [00:00<00:00, 628kB/s]
100%|##########| 206k/206k [00:00<00:00, 1.33MB/s]
subject_id scan_site_id ... dl_qc_score site_variant
0 sub-NDARAA306NT2 RU ... 0.470 RU_64dir_Most_Common
1 sub-NDARAA536PTU SI ... 0.701 SI_64dir_Obliquity
2 sub-NDARAA947ZG5 CBIC ... 0.509 CBIC_64dir_Most_Common
3 sub-NDARAA948VFH RU ... 0.979 RU_64dir_Most_Common
4 sub-NDARAB055BPR RU ... 0.035 RU_64dir_Most_Common
... ... ... ... ... ...
2129 sub-NDARZW873DN3 CBIC ... 0.982 CBIC_64dir_Most_Common
2130 sub-NDARZX163EWC CBIC ... 0.993 CBIC_64dir_Most_Common
2131 sub-NDARZY101JNB CBIC ... 0.992 CBIC_64dir_Most_Common
2132 sub-NDARZZ740MLM RU ... 0.014 RU_64dir_Most_Common
2133 sub-NDARZZ810LVF CBIC ... 0.861 CBIC_64dir_Most_Common
[2134 rows x 12 columns]
What we get is a DataFrame entailing the content of QSIprep’s participant.tsv file.
In contains various demographic variables but also the Quality Control scores we are interested in.
In order to make the respective evaluation more straightforward, we can use the datasets.get_HBN_qc() function,
which will sort the DataFrame based on the dl_qc_score variable. We can furthermore indicate how
many participants with the highest score, as well as if the sorted DataFrame
and a raincloud plot of the dl_qc_score variable across the dataset should be returned.
Here, we going to get the participants that have the 3 highest scores, the sorted DataFrame and the raincloud plot.
HBN_qc_participants_df_sorted = datasets.eval_HBN_qc(HBN_qc_file,
n_high_participants=3,
visualize=True, return_sorted_df=True)
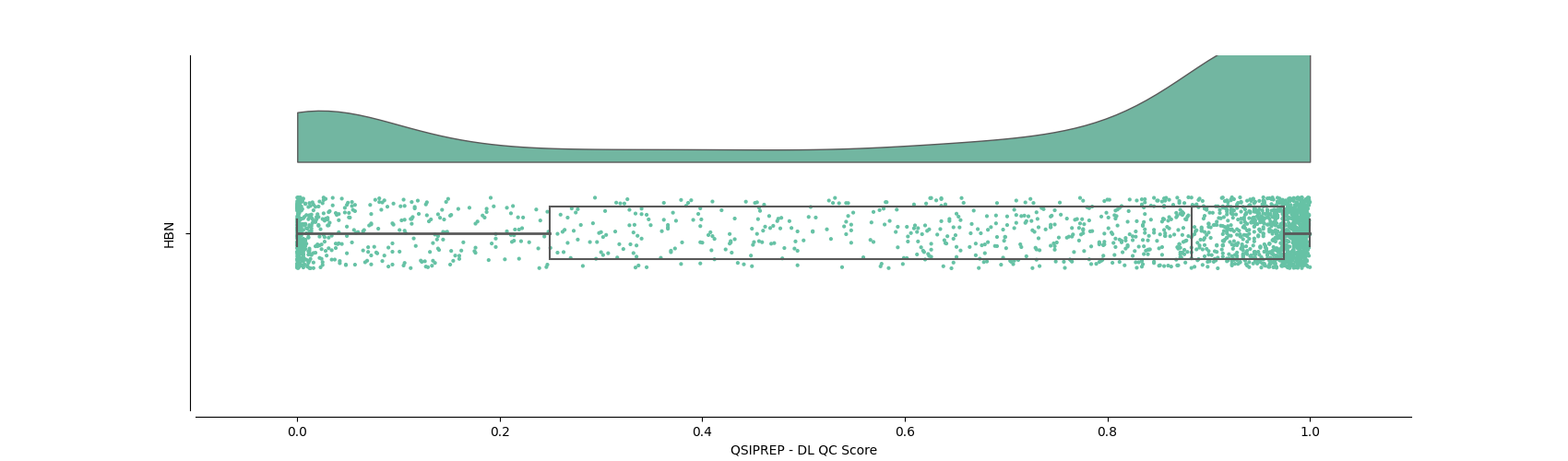
The 3 participants with the highest QC score are:
418 sub-NDAREK918EC2
2002 sub-NDARYM277DEA
1151 sub-NDARMV189NXG
Name: subject_id, dtype: object
/usr/share/miniconda/envs/bids_bep16_conv/lib/python3.8/site-packages/seaborn/_core.py:1303: UserWarning: Vertical orientation ignored with only `x` specified.
warnings.warn(single_var_warning.format("Vertical", "x"))
/usr/share/miniconda/envs/bids_bep16_conv/lib/python3.8/site-packages/seaborn/_core.py:1303: UserWarning: Vertical orientation ignored with only `x` specified.
warnings.warn(single_var_warning.format("Vertical", "x"))
/usr/share/miniconda/envs/bids_bep16_conv/lib/python3.8/site-packages/seaborn/_core.py:1303: UserWarning: Vertical orientation ignored with only `x` specified.
warnings.warn(single_var_warning.format("Vertical", "x"))
As you can see in the raincloud plot, the score has a rather interesting distribution but the
above obtained Series indicates that participant sub-NDAREK918EC2 has the
highest dl_qc_score. However, upon closer inspection it was noticed that this participant doesn’t
have all files necessary to test multiple analysis pipelines and the respective conversion to BEP16.
Thus, the participant’s data with the second highest dl_qc_score was utilized. This refers to
sub-NDARYM277DEA’s QSIprep outputs
which were downloaded from the FCP-INDI AWS bucket and subsequently
uploaded to the dataset component of the BIDS connectivity project OSF project
for access and management.
That being said, we can use datasets.download_HBN() function to download the respective data, for example
to our Desktop.
Downloading sub-NDARYM277DEA_ses-HBNsiteCBIC_acq-64dir_space-T1w_desc-preproc_dwi.bval
0%| | 0/642 [00:00<?, ?it/s]
100%|##########| 642/642 [00:00<00:00, 715kB/s]
Downloading sub-NDARYM277DEA_ses-HBNsiteCBIC_acq-64dir_space-T1w_desc-preproc_dwi.bvec
0%| | 0/4457 [00:00<?, ?it/s]
100%|##########| 4.35k/4.35k [00:00<00:00, 4.86MB/s]
Downloading sub-NDARYM277DEA_ses-HBNsiteCBIC_acq-64dir_space-T1w_desc-preproc_dwi.nii.gz
0%| | 0/359208318 [00:00<?, ?it/s]
0%| | 1.69M/343M [00:00<00:20, 17.7MB/s]
2%|2 | 8.00M/343M [00:00<00:07, 46.0MB/s]
4%|4 | 14.7M/343M [00:00<00:06, 55.5MB/s]
6%|5 | 20.0M/343M [00:00<00:06, 52.9MB/s]
8%|7 | 26.6M/343M [00:00<00:05, 55.9MB/s]
10%|9 | 33.8M/343M [00:00<00:05, 62.1MB/s]
12%|#1 | 39.8M/343M [00:00<00:05, 59.5MB/s]
13%|#3 | 45.5M/343M [00:00<00:05, 58.3MB/s]
15%|#5 | 52.2M/343M [00:00<00:05, 59.9MB/s]
17%|#6 | 58.0M/343M [00:01<00:04, 60.2MB/s]
19%|#8 | 64.1M/343M [00:01<00:04, 61.1MB/s]
20%|## | 69.9M/343M [00:01<00:04, 61.2MB/s]
22%|##2 | 75.8M/343M [00:01<00:04, 60.2MB/s]
24%|##4 | 82.2M/343M [00:01<00:04, 61.8MB/s]
26%|##5 | 88.2M/343M [00:01<00:04, 61.4MB/s]
27%|##7 | 94.1M/343M [00:01<00:04, 61.2MB/s]
29%|##9 | 100M/343M [00:01<00:04, 61.8MB/s]
31%|### | 106M/343M [00:01<00:04, 59.7MB/s]
33%|###2 | 112M/343M [00:01<00:03, 61.7MB/s]
35%|###4 | 118M/343M [00:02<00:03, 60.1MB/s]
36%|###6 | 124M/343M [00:02<00:03, 58.4MB/s]
38%|###8 | 131M/343M [00:02<00:03, 62.4MB/s]
40%|#### | 137M/343M [00:02<00:03, 60.2MB/s]
42%|####1 | 143M/343M [00:02<00:03, 58.3MB/s]
44%|####3 | 150M/343M [00:02<00:03, 60.4MB/s]
46%|####5 | 156M/343M [00:02<00:03, 62.3MB/s]
47%|####7 | 162M/343M [00:02<00:03, 57.2MB/s]
49%|####9 | 169M/343M [00:03<00:03, 57.1MB/s]
51%|#####1 | 175M/343M [00:03<00:02, 59.9MB/s]
53%|#####2 | 181M/343M [00:03<00:02, 59.5MB/s]
55%|#####4 | 187M/343M [00:03<00:02, 59.7MB/s]
56%|#####6 | 194M/343M [00:03<00:02, 61.6MB/s]
58%|#####8 | 199M/343M [00:03<00:02, 60.9MB/s]
60%|#####9 | 205M/343M [00:03<00:02, 60.9MB/s]
62%|######1 | 212M/343M [00:03<00:02, 61.6MB/s]
63%|######3 | 217M/343M [00:03<00:02, 61.3MB/s]
65%|######5 | 223M/343M [00:03<00:02, 61.2MB/s]
67%|######6 | 229M/343M [00:04<00:01, 60.5MB/s]
69%|######8 | 235M/343M [00:04<00:01, 60.4MB/s]
70%|####### | 241M/343M [00:04<00:01, 62.1MB/s]
72%|#######2 | 247M/343M [00:04<00:01, 61.4MB/s]
74%|#######3 | 253M/343M [00:04<00:01, 60.2MB/s]
76%|#######5 | 259M/343M [00:04<00:01, 60.0MB/s]
77%|#######7 | 265M/343M [00:04<00:01, 58.3MB/s]
79%|#######8 | 271M/343M [00:04<00:01, 58.3MB/s]
81%|########1 | 278M/343M [00:04<00:01, 58.8MB/s]
83%|########3 | 285M/343M [00:05<00:01, 59.4MB/s]
85%|########5 | 292M/343M [00:05<00:00, 62.0MB/s]
87%|########7 | 298M/343M [00:05<00:00, 61.8MB/s]
89%|########8 | 304M/343M [00:05<00:00, 59.7MB/s]
91%|######### | 310M/343M [00:05<00:00, 59.4MB/s]
93%|#########2| 317M/343M [00:05<00:00, 60.8MB/s]
94%|#########4| 323M/343M [00:05<00:00, 59.6MB/s]
96%|#########6| 329M/343M [00:05<00:00, 60.8MB/s]
98%|#########7| 335M/343M [00:05<00:00, 60.1MB/s]
99%|#########9| 341M/343M [00:05<00:00, 59.2MB/s]
100%|##########| 343M/343M [00:06<00:00, 59.8MB/s]
Downloading sub-NDARYM277DEA_ses-HBNsiteCBIC_acq-64dir_space-T1w_desc-brain_mask.nii.gz
0%| | 0/13243 [00:00<?, ?it/s]
100%|##########| 12.9k/12.9k [00:00<00:00, 13.6MB/s]
Downloading sub-NDARYM277DEA_ses-HBNsiteCBIC_acq-64dir_space-T1w_desc-preproc_dwi.json
0%| | 0/3250 [00:00<?, ?it/s]
100%|##########| 3.17k/3.17k [00:00<00:00, 3.57MB/s]
Downloading QSIprep/dataset_description.json
0%| | 0/499 [00:00<?, ?it/s]
100%|##########| 499/499 [00:00<00:00, 569kB/s]
Downloading HBN/dataset_description.json
0%| | 0/60 [00:00<?, ?it/s]
100%|##########| 60.0/60.0 [00:00<00:00, 66.2kB/s]
The following HBN files are available:
HBN/
├─dataset_description.json
├─derivatives/
│ └─QSIprep/
│ ├─dataset_description.json
│ └─sub-NDARYM277DEA/
│ └─ses-HBNsiteCBIC/
│ └─dwi/
│ ├─sub-NDARYM277DEA_ses-HBNsiteCBIC_acq-64dir_space-T1w_desc-preproc_dwi.json
│ ├─sub-NDARYM277DEA_ses-HBNsiteCBIC_acq-64dir_space-T1w_desc-preproc_dwi.bval
│ ├─sub-NDARYM277DEA_ses-HBNsiteCBIC_acq-64dir_space-T1w_desc-preproc_dwi.nii.gz
│ ├─sub-NDARYM277DEA_ses-HBNsiteCBIC_acq-64dir_space-T1w_desc-brain_mask.nii.gz
│ └─sub-NDARYM277DEA_ses-HBNsiteCBIC_acq-64dir_space-T1w_desc-preproc_dwi.bvec
└─source-HBN_desc-qsiprep_participants.tsv
Importantly, this function does not only obtain the participant’s QSIprep output, but
also obtains the dataset_description.json and generates the data json sidecar file required by
BIDS common derivatives.
The latter is achieved by downloading the
respective raw data json sidecar file and appending the needed inheritance-related & spatial reference-related information.
With that, we have a feasible HBN sub-dataset, confirming to
BIDS common derivatives,
as well as
inputs required by BEP16 and respective further processing.
Total running time of the script: ( 0 minutes 15.515 seconds)