Model evaluation & cross-validation
Contents
Model evaluation & cross-validation¶
Aim(s) of this section 🎯¶
As mention in the previous section, it is not sufficient to apply these methods to learn somthing about the nature of our data. It is always necessary to assess the quality of the implemented model. The goal of these section is to look at ways to estimate the generalization accuracy of a model on future (e.g.,unseen, out-of-sample) data.
In other words, at the end of these sections you should know:
different techniques to evaluate a given model
understand the basic idea of cross-validation and different kinds of the same
get an idea how to assess the significance (e.g., via permutation tests)
Outline for this section 📝¶
Model diagnostics
Cross-validation
Prepare data for model¶
Lets bring back our example data set (you know the song …)
import numpy as np
import pandas as pd
# get the data set
data = np.load('MAIN2019_BASC064_subsamp_features.npz')['a']
# get the labels
info = pd.read_csv('participants.csv')
print('There are %s samples and %s features' % (data.shape[0], data.shape[1]))
There are 155 samples and 2016 features
Now let’s look at the labels
info.head(n=5)
| participant_id | Age | AgeGroup | Child_Adult | Gender | Handedness | |
|---|---|---|---|---|---|---|
| 0 | sub-pixar123 | 27.06 | Adult | adult | F | R |
| 1 | sub-pixar124 | 33.44 | Adult | adult | M | R |
| 2 | sub-pixar125 | 31.00 | Adult | adult | M | R |
| 3 | sub-pixar126 | 19.00 | Adult | adult | F | R |
| 4 | sub-pixar127 | 23.00 | Adult | adult | F | R |
We’ll set Age as target
i.e., well look at these from the
regressionperspective
# set age as target
Y_con = info['Age']
Y_con.describe()
count 155.000000
mean 10.555189
std 8.071957
min 3.518138
25% 5.300000
50% 7.680000
75% 10.975000
max 39.000000
Name: Age, dtype: float64
Next:
we need to divide our input data
Xintotrainingandtestsets
# import necessary python modules
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
from sklearn.pipeline import make_pipeline
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# split the data
X_train, X_test, y_train, y_test = train_test_split(data, Y_con, random_state=0)
Now lets look at the size of the data sets
# print the size of our training and test groups
print('N used for training:', len(X_train),
' | N used for testing:', len(X_test))
N used for training: 116 | N used for testing: 39
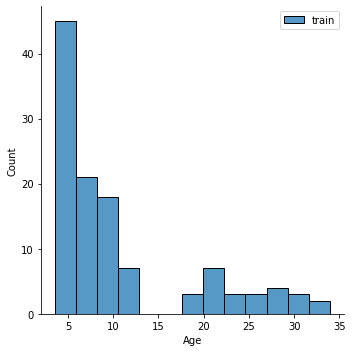
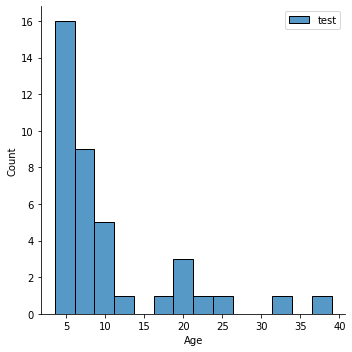
Question: Is that a good distribution? Does it look ok?
Why might this be problematic (hint: what do you know about groups (e.g.,
Child_Adult) in the data.
import matplotlib.pyplot as plt
import seaborn as sns
sns.displot(y_train,label='train')
plt.legend()
sns.displot(y_test,label='test')
plt.legend()
<matplotlib.legend.Legend at 0x7fd36fa08400>
Model fit¶
Now lets go ahead and fit the model
we will use a fairly standard regression model called a Support Vector Regressor (SVR)
similar to the one we used in the previous section
from sklearn.svm import SVR
# define the model
lin_svr = SVR(kernel='linear')
# fit the model
lin_svr.fit(X_train, y_train)
SVR(kernel='linear')
Model diagnostics¶
Now let’s look at how the model performs in predicting the data
we can use the
scoremethod to calculate the coefficient of determination (or R-squared) of the prediction.for this we compare the observed data to the predicted data
# predict the training data based on the model
y_pred = lin_svr.predict(X_train)
# caluclate the model accuracy
acc = lin_svr.score(X_train, y_train)
# print results
print('accuracy (R2)', acc)
accuracy (R2) 0.9998468951478122
Now lets plot the predicted values
sns.regplot(y=y_pred, x=y_train, scatter_kws=dict(color='k'))
plt.xlabel('Predicted Age')
Text(0.5, 0, 'Predicted Age')
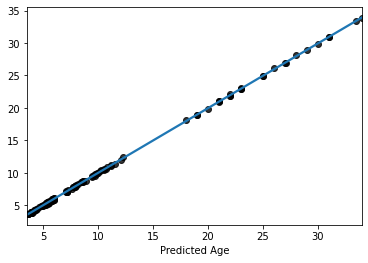
Now thats really cool, eh? Almost a perfect fit
… which means something is wrong
what are we missing here?
recall: We are still using the test data sets.

Train/test stratification¶
Now lets do this again but we’ll add some constraints to the predriction
Well keey the 75/25 ratio between test and train data sets
But now we will try to keep the characteristics of the data set consistent accross training and test datasets
For this we will use something called stratification
# use `AgeGroup` for stratification
age_class2 = info.loc[y_train.index,'AgeGroup']
# split the data
X_train2, X_test, y_train2, y_test = train_test_split(
X_train, # x
y_train, # y
test_size = 0.25, # 75%/25% split
shuffle = True, # shuffle dataset before splitting
stratify = age_class2, # keep distribution of age class consistent
# betw. train & test sets.
random_state = 0 # same shuffle each time
)
Let’s re-fit the model on the newly computed (and stratified) train data and evaluate it’ performace on an (also stratified) test data
We’ll compute again the model accuracy (R-squared) to evalueate the models performance,
but we’ll also have a look at the mean-absolute-error (MAE), it is measured as the average sum of the absolute diffrences between predictions and actual observations. Unlike other measures, MAE is more robust to outliers, since it doesn’t square the deviations (cf. mean-squared-error)
it provides a way to asses “how far off” are our predictions from our actual data, while staying on it’s referential space
from sklearn.metrics import mean_absolute_error
# fit model just to training data
lin_svr.fit(X_train2, y_train2)
# predict the *test* data based on the model trained on X_train2
y_pred = lin_svr.predict(X_test)
# calculate the model accuracy
acc = lin_svr.score(X_test, y_test)
mae = mean_absolute_error(y_true=y_test,y_pred=y_pred)
Lets check the results
# print results
print('accuracy (R2) = ', acc)
print('MAE = ', mae)
accuracy (R2) = 0.6593855081680796
MAE = 3.2059201603105882
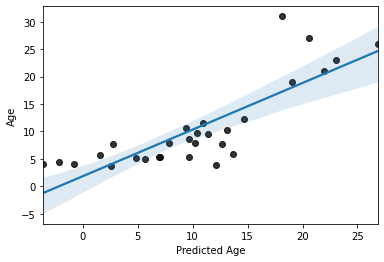
# plot results
sns.regplot(x=y_pred,y=y_test, scatter_kws=dict(color='k'))
plt.xlabel('Predicted Age')
Text(0.5, 0, 'Predicted Age')
Cross-validation¶
Not perfect, but its not bad, as far as predicting with unseen data goes. Especially with a training sample of “only” 69 subjects.
But, can we do better?
On thing we could do is increase the size our training set while simultaneously reducing bias by instead using 10-fold cross-validation

Cross-validation is a technique used to protect against biases in a predictive model
particularly useful in cases where the amount of data may be limited.
basic idea: you partition the data in a fixed number of folds, run the analysis on each fold, and then average out the overall error estimate
Let’s look at the models performance across 10 folds
# import modules needed for cross-validation
from sklearn.model_selection import cross_val_predict, cross_val_score
# predict
y_pred = cross_val_predict(lin_svr, X_train, y_train, cv=10)
# scores
acc = cross_val_score(lin_svr, X_train, y_train, cv=10)
mae = cross_val_score(lin_svr, X_train, y_train, cv=10,
scoring='neg_mean_absolute_error')
# negative MAE is simply the negative of the
# MAE (by definition a positive quantity),
# since MAE is an error metric, i.e. the lower the better,
# negative MAE is the opposite
# print the results for each fold
for i in range(10):
print(
'Fold {} -- Acc = {}, MAE = {}'.format(i, np.round(acc[i], 3), np.round(-mae[i], 3))
)
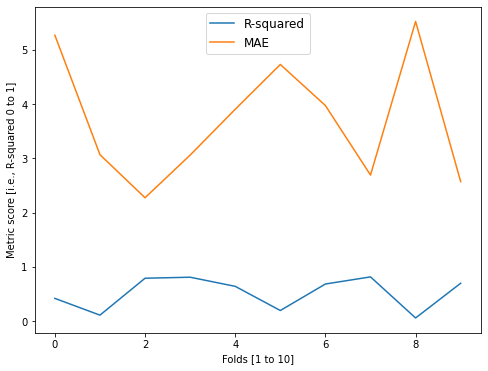
Fold 0 -- Acc = 0.419, MAE = 5.271
Fold 1 -- Acc = 0.11, MAE = 3.069
Fold 2 -- Acc = 0.79, MAE = 2.275
Fold 3 -- Acc = 0.809, MAE = 3.061
Fold 4 -- Acc = 0.641, MAE = 3.906
Fold 5 -- Acc = 0.195, MAE = 4.732
Fold 6 -- Acc = 0.684, MAE = 3.974
Fold 7 -- Acc = 0.815, MAE = 2.693
Fold 8 -- Acc = 0.058, MAE = 5.525
Fold 9 -- Acc = 0.698, MAE = 2.571
For the visually oriented among us
fig = plt.figure(figsize=(8, 6))
plt.plot(acc, label = 'R-squared')
plt.legend()
plt.plot(-mae, label = 'MAE')
plt.legend(prop={'size': 12}, loc=9)
plt.xlabel('Folds [1 to 10]')
plt.ylabel('Metric score [i.e., R-squared 0 to 1]')
Text(0, 0.5, 'Metric score [i.e., R-squared 0 to 1]')
We can also look at the overall accuracy of the model
from sklearn.metrics import r2_score
overall_acc = r2_score(y_train, y_pred)
overall_mae = mean_absolute_error(y_train, y_pred)
print('R2:', overall_acc)
print('MAE:', overall_mae)
R2: 0.5544107024745264
MAE: 3.7082530497804926
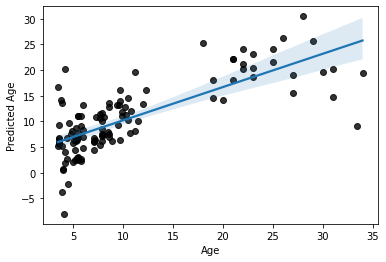
Now, let’s look at the final overall model prediction
sns.regplot(x=y_train, y=y_pred, scatter_kws=dict(color='k'))
plt.ylabel('Predicted Age')
Text(0, 0.5, 'Predicted Age')
Summary¶
Not bad, not bad at all.
But most importantly
this is a more accurate estimation of our model’s predictive efficacy.