Structural connectivity and diffusion imaging
Contents
Structural connectivity and diffusion imaging¶
Structural connectivity or diffusion imaging can be studied in many different way. Dipy is only one of them. Dipy is focusing mainly on diffusion magnetic resonance imaging (dMRI) analysis and implements a broad range of algorithms for denoising, registration, reconstruction, tracking, clustering, visualization, and statistical analysis of dMRI data. For a more detailed guide and a lot of examples go to Dipy, here we want to show you just a few basics.
Speaking of which, we will be covering the following sections:
Reconstruction of the diffusion signal with the Tensor model
Other reconstruction approaches, such as sparse fascicle models (SFM)
Introduction to Tractography
Using Various Tissue Classifiers for Tractography
Connectivity Matrices, ROI Intersections, and Density Maps
Direct Bundle Registration
General disclaimer: This notebook was written by somebody who is not an expert in diffusion imaging analysis. Therefore, certain steps might not be useful or not used in an actual analysis. Keep this in mind while going through this notebook.
Important: The rendering of the diffusion images is this notebook is a bit tricky and additionally dependent on the computing environment you are using to follow this workshop. Thus, a lot of sections unfortunately don’t have visualization. Sorry for that! Please make sure to check out the Dipy documentation.
Setup¶
Before we start with anything, let’s setup the important plotting functions:
from nilearn import plotting
%matplotlib inline
import matplotlib.pyplot as plt
import nibabel as nb
import numpy as np
from IPython.display import Image
Explore the tutorial dataset¶
For this tutorial, we will be using the Stanford HARDI dataset, provided with Dipy. You can download the required datasets with the following commands:
from dipy.data import (read_stanford_labels, read_stanford_t1,
read_stanford_pve_maps)
img, gtab, labels_img = read_stanford_labels()
t1 = read_stanford_t1()
pve_csf, pve_gm, pve_wm = read_stanford_pve_maps()
from dipy.data import (read_stanford_labels, read_stanford_t1,
read_stanford_pve_maps)
img, gtab, labels_img = read_stanford_labels()
t1 = read_stanford_t1()
pve_csf, pve_gm, pve_wm = read_stanford_pve_maps()
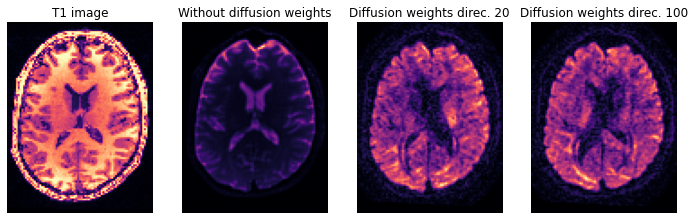
So what do we have?
axial_middle = img.shape[2] // 2
plt.figure(figsize=(12, 4))
plt.subplot(1, 4, 1).set_axis_off()
plt.imshow(t1.get_fdata()[:, :, axial_middle].T, cmap='magma', origin='lower')
plt.title('T1 image')
plt.subplot(1, 4, 2).set_axis_off()
plt.imshow(img.get_fdata()[:, :, axial_middle, 0].T, cmap='magma', origin='lower')
plt.title('Without diffusion weights')
plt.subplot(1, 4, 3).set_axis_off()
plt.imshow(img.get_fdata()[:, :, axial_middle, 30].T, cmap='magma', origin='lower')
plt.title('Diffusion weights direc. 20')
plt.subplot(1, 4, 4).set_axis_off()
plt.imshow(img.get_fdata()[:, :, axial_middle, 110].T, cmap='magma', origin='lower')
plt.title('Diffusion weights direc. 100')
Text(0.5, 1.0, 'Diffusion weights direc. 100')
plt.figure(figsize=(12, 4))
plt.subplot(1, 4, 1).set_axis_off()
plt.imshow(labels_img.get_fdata()[:, :, axial_middle].T, cmap='nipy_spectral', origin='lower')
plt.title('Volume labels')
plt.subplot(1, 4, 2).set_axis_off()
plt.imshow(pve_csf.get_fdata()[:, :, axial_middle].T, cmap='magma', origin='lower')
plt.title('CSF segmentation')
plt.subplot(1, 4, 3).set_axis_off()
plt.imshow(pve_gm.get_fdata()[:, :, axial_middle].T, cmap='magma', origin='lower')
plt.title('GM segmentation')
plt.subplot(1, 4, 4).set_axis_off()
plt.imshow(pve_wm.get_fdata()[:, :, axial_middle].T, cmap='magma', origin='lower')
plt.title('WM segmentation')
Text(0.5, 1.0, 'WM segmentation')
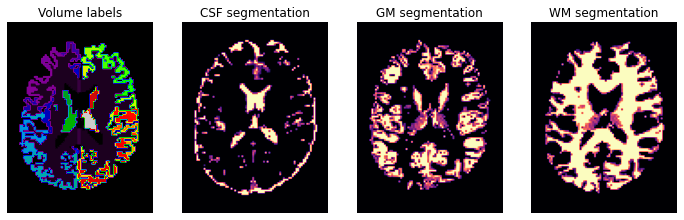
In diffusion MRI (dMRI) usually we use three types of files, a Nifti file with the diffusion weighted data (here hardi_img.nii.gz), and two text files one with b-values and one with the b-vectors. So let’s also check those two files, starting with b-values:
print(gtab.bvals)
[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 2000. 2000.
2000. 2000. 2000. 2000. 2000. 2000. 2000. 2000. 2000. 2000. 2000. 2000.
2000. 2000. 2000. 2000. 2000. 2000. 2000. 2000. 2000. 2000. 2000. 2000.
2000. 2000. 2000. 2000. 2000. 2000. 2000. 2000. 2000. 2000. 2000. 2000.
2000. 2000. 2000. 2000. 2000. 2000. 2000. 2000. 2000. 2000. 2000. 2000.
2000. 2000. 2000. 2000. 2000. 2000. 2000. 2000. 2000. 2000. 2000. 2000.
2000. 2000. 2000. 2000. 2000. 2000. 2000. 2000. 2000. 2000. 2000. 2000.
2000. 2000. 2000. 2000. 2000. 2000. 2000. 2000. 2000. 2000. 2000. 2000.
2000. 2000. 2000. 2000. 2000. 2000. 2000. 2000. 2000. 2000. 2000. 2000.
2000. 2000. 2000. 2000. 2000. 2000. 2000. 2000. 2000. 2000. 2000. 2000.
2000. 2000. 2000. 2000. 2000. 2000. 2000. 2000. 2000. 2000. 2000. 2000.
2000. 2000. 2000. 2000. 2000. 2000. 2000. 2000. 2000. 2000. 2000. 2000.
2000. 2000. 2000. 2000. 2000. 2000. 2000. 2000. 2000. 2000. 2000. 2000.
2000. 2000. 2000. 2000.]
For example the last 10 b-vectors:
print(gtab.bvecs[-10:, :])
[[ 0.50924 0.2046 -0.83595 ]
[-0.50611 -0.85336 -0.12505 ]
[ 0.7696 -0.35989 0.52745 ]
[ 0.73579 0.19537 -0.64841 ]
[-0.90321 0.32539 0.27989 ]
[-0.66243 -0.29331 -0.68931 ]
[ 0.5852 0.74103 0.32927 ]
[-0.17711 -0.70962 0.68196 ]
[ 0.16554 -0.2838 -0.94449 ]
[ 0.97435 0.0049151 0.22501 ]]
Now, that we learned how to load dMRI datasets we can start the analysis.
Reconstruction of the diffusion signal with the Tensor model¶
The diffusion tensor model is a model that describes the diffusion within a voxel. In short, for each voxel, we can estimate a tensor that had orientation and a particular tensor shape that indicates the primary diffusion directions of water in this voxel. For more details, check out the full example on the dipy homepage.
Preparation¶
data = img.get_fdata()
print('data shape before masking: (%d, %d, %d, %d)' % data.shape)
data shape before masking: (81, 106, 76, 160)
To avoid the calculation of the Tensors in the background of the image, we first need to mask and crop the data. For this, we can use Dipy’s mask module.
from dipy.segment.mask import median_otsu
maskdata, mask = median_otsu(data, vol_idx=range(10,50), median_radius=3, numpass=1, autocrop=True, dilate=2)
print('data shape after masking (%d, %d, %d, %d)' % maskdata.shape)
data shape after masking (71, 88, 62, 160)
Tensor reconstruction¶
Now that we have prepared the datasets we can go forward with the voxel reconstruction. First, we instantiate the Tensor model in the following way.
import dipy.reconst.dti as dti
tenmodel = dti.TensorModel(gtab)
Now we can fit the data to the model. This is very simple. We just need to call the fit method of the TensorModel in the following way:
tenfit = tenmodel.fit(maskdata)
Now that we have the model fit, we can quickly extract the fractional anisotropy (FA) or the mean diffusivity (MD) from the eigenvalues of the tensor. FA is used to characterize the degree to which the distribution of diffusion in a voxel is directional. That is, whether there is relatively unrestricted diffusion in one particular direction. The MD is simply the mean of the eigenvalues of the tensor. Since FA is a normalized measure of variance and MD is the mean, they are often used as complementary measures.
from dipy.reconst.dti import fractional_anisotropy, mean_diffusivity
FA = fractional_anisotropy(tenfit.evals)
MD = mean_diffusivity(tenfit.evals)
So what do they look like?
plotting.plot_anat(nb.Nifti1Image(FA, img.affine, img.header), cut_coords=[0,-20,0],
dim=-1, draw_cross=False, cmap='magma', title='FA')
plotting.plot_anat(nb.Nifti1Image(MD, img.affine, img.header), cut_coords=[0,-20,0],
dim=-1, draw_cross=False, cmap='magma', title='MD', vmax=0.001)
<nilearn.plotting.displays.OrthoSlicer at 0x7f0eb46c1890>
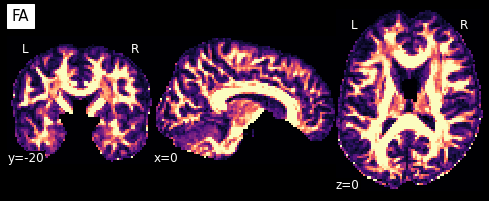
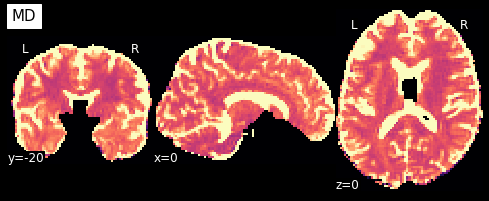
We can also compute the colored FA or RGB-map (Pajevic et al., 1999). First, we make sure that the FA is scaled between 0 and 1, we compute the RGB map and save it.
from dipy.reconst.dti import color_fa
RGB = color_fa(FA, tenfit.evecs)
# Let's visualize this
plt.figure(figsize=(6, 6))
plt.imshow(RGB[:, :, 31,:])
plt.axis('off');
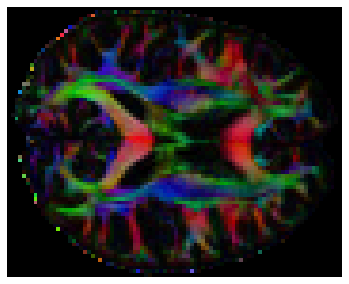
Other reconstruction approaches¶
Dipy offers many different reconstruction models, such as Constrained Spherical Deconvolution, Continuous Axially Symmetric Tensors, Q-Ball Constant Solid Angle, Sparse Fascicle Model and many more. For a full list check out the Reconstruction section on dipy.org.
But to show you how easy it is to change the reconstruction model, let’s take a loop at the Sparse Fascicle Model (Rokem et al., 2015). In very short, sparse fascicle models (SFM) try to control for the noise due to variance, and over-fitting, by means of regularization by limiting the number of fascicles in the estimated solution.
Create Model¶
Just like in Constrained Spherical Deconvolution (see Reconstruction with Constrained Spherical Deconvolution), the SFM requires the definition of a response function. We’ll take advantage of the automated algorithm in the csdeconv module to find this response function:
from dipy.reconst.csdeconv import auto_response
response, ratio = auto_response(gtab, data, roi_radius=10, fa_thr=0.7)
/opt/miniconda-latest/envs/neuro/lib/python3.7/site-packages/ipykernel_launcher.py:2: DeprecationWarning: dipy.reconst.csdeconv.auto_response is deprecated, Please use dipy.reconst.csdeconv.auto_response_ssst instead
* deprecated from version: 1.2
* Will raise <class 'dipy.utils.deprecator.ExpiredDeprecationError'> as of version: 1.4
/opt/miniconda-latest/envs/neuro/lib/python3.7/site-packages/dipy/reconst/csdeconv.py:80: UserWarning: Parameter `roi_radius` is now called `roi_radii` and can be an
array-like (3,). Parameters `fa_callable` and `return_number_of_voxels`
are not used anymore.
warnings.warn(msg, UserWarning)
The response return value contains two entries. The first is an array with the eigenvalues of the response function and the second is the average S0 for this response. It is a very good practice to always validate the result of auto_response. For, this purpose we can print it and have a look at its values.
print(response)
(array([0.00139919, 0.0003007 , 0.0003007 ]), 416.7372408293461)
We initialize an SFM model object, using these values. We will use the default sphere (362 vertices, symmetrically distributed on the surface of the sphere), as a set of putative fascicle directions that are considered in the model.
from dipy.data import get_sphere
sphere = get_sphere('symmetric362')
import dipy.reconst.sfm as sfm
sf_model = sfm.SparseFascicleModel(gtab, sphere=sphere,
l1_ratio=0.5, alpha=0.001,
response=response[0])
As before, let’s focus on the small volume of data containing parts of the corpus callosum and of the centrum semiovale.
data_small = data[20:50, 55:85, 38:39]
Fit Model & Visualize results¶
Fitting the model to this small volume of data, we calculate the ODF of this model on the sphere and plot it.
sf_fit = sf_model.fit(data_small)
sf_odf = sf_fit.odf(sphere)
from dipy.viz import window, actor
ren = window.Scene()
fodf_spheres = actor.odf_slicer(sf_odf, sphere=sphere, scale=0.8, colormap='plasma')
ren.add(fodf_spheres)
/opt/miniconda-latest/envs/neuro/lib/python3.7/site-packages/fury/actor.py:956: RuntimeWarning: invalid value encountered in true_divide
m /= np.abs(m).max()
We can extract the peaks from the ODF, and plot these as well.
import dipy.direction.peaks as dpp
sf_peaks = dpp.peaks_from_model(sf_model,
data_small,
sphere,
relative_peak_threshold=.5,
min_separation_angle=25,
return_sh=False)
# Let's render these peaks as well
fodf_peaks = actor.peak_slicer(sf_peaks.peak_dirs, sf_peaks.peak_values)
ren.add(fodf_peaks)
Finally, we can plot both the peaks and the ODFs, overlayed:
fodf_spheres.GetProperty().SetOpacity(0.4)
ren.add(fodf_spheres)
Introduction to Tractography¶
Local fiber tracking is an approach used to model white matter fibers by creating streamlines from local directional information. The idea is as follows: if the local directionality of a tract/pathway segment is known, one can integrate along those directions to build a complete representation of that structure. Local fiber tracking is widely used in the field of diffusion MRI because it is simple and robust.
In order to perform local fiber tracking, three things are needed:
A method for getting directions from a diffusion data set.
A method for identifying different tissue types within the data set.
A set of seeds from which to begin tracking.
Here we will use Constrained Spherical Deconvolution (CSD) Tournier et al., 2007 for local reconstruction and then generate deterministic streamlines using the fiber directions (peaks) from CSD and fractional anisotropic (FA) from DTI as stopping criteria for the tracking. As before, we will be using the masked Stanford HARDI dataset.
Estimate the response function and create a model¶
For the Constrained Spherical Deconvolution we need to estimate the response function (see Reconstruction with Constrained Spherical Deconvolution) and create a model.
from dipy.reconst.csdeconv import ConstrainedSphericalDeconvModel, auto_response
response, ratio = auto_response(gtab, data, roi_radius=10, fa_thr=0.7)
csd_model = ConstrainedSphericalDeconvModel(gtab, response)
/opt/miniconda-latest/envs/neuro/lib/python3.7/site-packages/ipykernel_launcher.py:3: DeprecationWarning: dipy.reconst.csdeconv.auto_response is deprecated, Please use dipy.reconst.csdeconv.auto_response_ssst instead
* deprecated from version: 1.2
* Will raise <class 'dipy.utils.deprecator.ExpiredDeprecationError'> as of version: 1.4
This is separate from the ipykernel package so we can avoid doing imports until
/opt/miniconda-latest/envs/neuro/lib/python3.7/site-packages/dipy/reconst/csdeconv.py:80: UserWarning: Parameter `roi_radius` is now called `roi_radii` and can be an
array-like (3,). Parameters `fa_callable` and `return_number_of_voxels`
are not used anymore.
warnings.warn(msg, UserWarning)
Model fit and computation of fiber direction¶
Next, we use peaks_from_model to fit the data and calculated the fiber directions in all voxels.
from dipy.data import get_sphere
sphere = get_sphere('symmetric724')
from dipy.segment.mask import median_otsu
maskdata, mask = median_otsu(data, vol_idx=range(10,50), median_radius=3, numpass=1, autocrop=False, dilate=2)
%%time
from dipy.direction import peaks_from_model
csd_peaks = peaks_from_model(model=csd_model,
data=data,
sphere=sphere,
mask=mask,
relative_peak_threshold=.5,
min_separation_angle=25,
parallel=True)
CPU times: user 5.3 s, sys: 5.79 s, total: 11.1 s
Wall time: 9min 32s
Fiber tracking¶
For the tracking part, we will use the fiber directions from the csd_model but stop tracking in areas where fractional anisotropy is low (< 0.1). To derive the FA, used here as a stopping criterion, we would need to fit a tensor model first. Here, we fit the tensor using weighted least squares (WLS).
from dipy.reconst.dti import TensorModel
tensor_model = TensorModel(gtab, fit_method='WLS')
tensor_fit = tensor_model.fit(data, mask)
fa = tensor_fit.fa
In this simple example we can use FA to stop tracking. Here we stop tracking when FA < 0.1.
from dipy.tracking.stopping_criterion import ThresholdStoppingCriterion
tissue_classifier = ThresholdStoppingCriterion(fa, 0.25)
Now, we need to set starting points for propagating each track. We call those seeds. Using random_seeds_from_mask we can select a specific number of seeds (seeds_count) in each voxel where the mask fa > 0.3 is true.
from dipy.tracking.utils import random_seeds_from_mask
seeds = random_seeds_from_mask(fa > 0.5, seeds_count=1, affine=np.eye(4))
For quality assurance, let’s visualize a slice from the direction field which we will use as the basis to perform the tracking.
from dipy.viz import window, actor
ren = window.Scene()
ren.add(actor.peak_slicer(csd_peaks.peak_dirs,
csd_peaks.peak_values,
colors=None))
Streamline generation¶
Now that we have the direction field, we can generate the streamlines of the tractography.
from dipy.tracking.local_tracking import LocalTracking
streamline_generator = LocalTracking(csd_peaks, tissue_classifier,
seeds, affine=np.eye(4),
step_size=0.5)
from dipy.tracking.streamline import Streamlines
streamlines = Streamlines(streamline_generator)
The total number of streamlines can be check as follows:
print(len(streamlines))
26066
To increase the number of streamlines you can change the parameter seeds_count in random_seeds_from_mask.
Visualize streamlines¶
Now that we have everything we can visualize the streamlines using actor.line or actor.streamtube.
from dipy.viz import window, actor
ren = window.Scene()
ren.add(actor.line(streamlines))
Using Various Tissue Classifiers for Tractography¶
The tissue classifier determines if the tracking stops or continues at each tracking position. The tracking stops when it reaches an ending region (e.g. low FA, gray matter or corticospinal fluid regions) or exits the image boundaries. The tracking also stops if the direction getter has no direction to follow.
In this example we want to show how you can use the white matter voxels of the corpus callosum to use as a seed mask from which the streamlines should start. For this we first need to create a corpus callosum mask. This we can get from the labels_img:
plotting.plot_anat(labels_img, cut_coords=[0,-20,0], dim=-1,
draw_cross=False, cmap='nipy_spectral', title='labels')
<nilearn.plotting.displays.OrthoSlicer at 0x7f0e79223dd0>

In this label image file, label 2 represents the corpus callosum. So let’s create a mask from this:
cc_mask = np.array(labels_img.get_fdata()==2, dtype='int')
plotting.plot_anat(nb.Nifti1Image(cc_mask, img.affine, img.header), cut_coords=[0,-20,0],
dim=-1, draw_cross=False, cmap='magma', title='Corpus callosum')
<nilearn.plotting.displays.OrthoSlicer at 0x7f0e793f8d90>
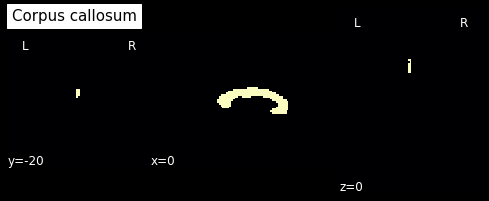
from dipy.tracking import utils
seeds = utils.seeds_from_mask(cc_mask, density=2, affine=img.affine)
Now that we have the mask, we can run the streamline generator again, but this time using the corpus callosum mask as a seed region.
from dipy.tracking.local_tracking import LocalTracking
streamline_generator = LocalTracking(csd_peaks,
tissue_classifier,
seeds,
affine=img.affine,
step_size=0.1)
from dipy.tracking.streamline import Streamlines
streamlines = Streamlines(streamline_generator)
Visualizing the corpus callosum fiber tracts¶
from dipy.viz import window, actor
ren = window.Scene()
ren.add(actor.line(streamlines))
Connectivity Matrices, ROI Intersections, and Density Maps¶
This example is meant to be an introduction to some of the streamline tools available in Dipy. Some of the functions covered in this example are:
targetallows one to filter streamlines that either pass through or do not pass through some region of the brainconnectivity_matrixgroups and counts streamlines based on where in the brain they begin and enddensity mapcounts the number of streamlines that pass through every voxel of some image.
Create the tractography¶
To get started we’ll need to have a set of streamlines to work with. We will use again the Stanford HARDI dataset and use EuDX along with the CsaOdfModel to make some streamlines.
We’ll use peaks_from_model to apply the CsaOdfModel to each white matter voxel and estimate fiber orientations which we can use for tracking:
from dipy.data import read_stanford_labels, read_stanford_t1
hardi_img, gtab, labels_img = read_stanford_labels()
data = hardi_img.get_fdata()
labels = labels_img.get_fdata()
t1 = read_stanford_t1()
t1_data = t1.get_fdata()
We’ve loaded an image called labels_img which is a map of tissue types such that every integer value in the array labels represents an anatomical structure or tissue type 1. For this example, the image was created so that white matter voxels have values of either 1 or 2. We’ll use peaks_from_model to apply the CsaOdfModel to each white matter voxel and estimate fiber orientations which we can use for tracking. We will also dilate this mask by 1 voxel to ensure streamlines reach the grey matter.
from dipy.reconst import shm
from dipy.direction import peaks
from scipy.ndimage.morphology import binary_dilation
white_matter = binary_dilation((labels == 1) | (labels == 2))
csamodel = shm.CsaOdfModel(gtab, 6)
csapeaks = peaks.peaks_from_model(model=csamodel,
data=data,
sphere=peaks.default_sphere,
relative_peak_threshold=.8,
min_separation_angle=45,
mask=white_matter)
Now we can use EuDX to track all of the white matter. To keep things reasonably fast we use density=1 which will result in 1 seeds per voxel. We’ll set a_low (the parameter which determines the threshold of FA/QA under which tracking stops) to be very low because we’ve already applied a white matter mask.
from dipy.tracking import utils
from dipy.tracking.local_tracking import LocalTracking
from dipy.tracking.stopping_criterion import BinaryStoppingCriterion
from dipy.tracking.streamline import Streamlines
affine = np.eye(4)
seeds = utils.seeds_from_mask(white_matter, affine, density=1)
stopping_criterion = BinaryStoppingCriterion(white_matter)
streamline_generator = LocalTracking(csapeaks, stopping_criterion, seeds,
affine=affine, step_size=0.5)
streamlines = Streamlines(streamline_generator)
The first of the tracking utilities we’ll cover here is target. This function takes a set of streamlines and a region of interest (ROI) and returns only those streamlines that pass through the ROI. The ROI should be an array such that the voxels that belong to the ROI are True and all other voxels are False (this type of binary array is sometimes called a mask). This function can also exclude all the streamlines that pass through an ROI by setting the include flag to False.
In this example, we’ll target the streamlines of the corpus callosum. Our labels array has a sagittal slice of the corpus callosum identified by the label value 2. We’ll create an ROI mask from that label and create two sets of streamlines, those that intersect with the ROI and those that don’t.
%%time
cc_slice = labels == 2
cc_streamlines = utils.target(streamlines, affine, cc_slice)
cc_streamlines = Streamlines(cc_streamlines)
other_streamlines = utils.target(streamlines, affine, cc_slice,
include=False)
other_streamlines = Streamlines(other_streamlines)
assert len(other_streamlines) + len(cc_streamlines) == len(streamlines)
CPU times: user 10.9 s, sys: 604 ms, total: 11.6 s
Wall time: 11 s
Create the connectivity matrix¶
Once we’ve targeted on the corpus callosum ROI, we might want to find out which regions of the brain are connected by these streamlines. To do this we can use the connectivity_matrix function. This function takes a set of streamlines and an array of labels as arguments. It returns the number of streamlines that start and end at each pair of labels and it can return the streamlines grouped by their endpoints. Notice that this function only considers the endpoints of each streamline. Because we’re typically only interested in connections between gray matter regions, and because the label 0 represents background and the labels 1 and 2 represent white matter, we discard the first three rows and columns of the connectivity matrix.
M, grouping = utils.connectivity_matrix(cc_streamlines, affine, labels.astype('int'),
return_mapping=True,
mapping_as_streamlines=True)
M[:3, :] = 0
M[:, :3] = 0
We’ve set return_mapping and mapping_as_streamlines to True so that connectivity_matrix returns all the streamlines in cc_streamlines grouped by their endpoint.
We can now display this matrix using matplotlib. We display it using a log scale to make small values in the matrix easier to see.
import numpy as np
import matplotlib.pyplot as plt
plt.imshow(np.log1p(M), interpolation='nearest')
plt.savefig("connectivity.png")
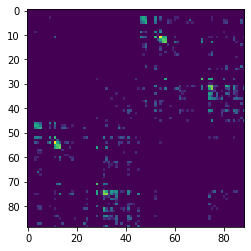
In our example track, there are more streamlines connecting regions 11 and 54 than any other pair of regions. These labels represent the left and right superior frontal gyrus respectively. These two regions are large, close together, have lots of corpus callosum fibers and are easy to track so this result should not be a surprise to anyone.
However, the interpretation of streamline counts can be tricky. The relationship between the underlying biology and the streamline counts will depend on several factors, including how the tracking was done, and the correct way to interpret these kinds of connectivity matrices is still an open question in the diffusion imaging literature.
Compute density map¶
The next function we’ll demonstrate is density_map. This function allows one to represent the spatial distribution of a track by counting the density of streamlines in each voxel.
For example, let’s take the track connecting the left and right superior frontal gyrus.
lr_superiorfrontal_track = grouping[11, 54]
shape = labels.shape
dm = utils.density_map(lr_superiorfrontal_track, affine, shape)
Let’s save this density map and visualize it
# Save density map
dm_img = nb.Nifti1Image(dm.astype("int16"), img.affine)
plotting.plot_anat(dm_img, cut_coords=[12,10,34], dim=-1, draw_cross=False,
cmap='magma', title='Density Map of Region 11 & 54')
<nilearn.plotting.displays.OrthoSlicer at 0x7f0eb7ce0150>
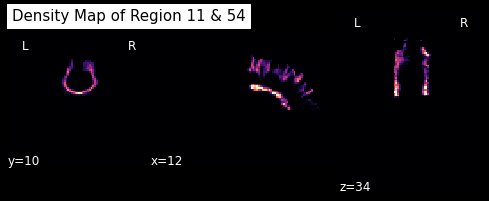
Direct Bundle Registration¶
Creating different tractographies is cool and looks very pleasing, but what if we want to compare the tractography of two people, where the bundles don’t align? No worries, Dipy has the solution: Bundle registration
To show the concept we will use two pre-saved cingulum bundles.
from dipy.data import two_cingulum_bundles
cb_subj1, cb_subj2 = two_cingulum_bundles()
The algorithm we will be using is called Streamline-based Linear Registration (SLR) Garyfallidis et al., 2015. An important step before running the registration is to resample the streamlines so that they both have the same number of points per streamline. Here we will use 20 points. This step is not optional. Inputting streamlines with different number of points will break the theoretical advantages of using the SLR.
from dipy.tracking.streamline import set_number_of_points
cb_subj1 = set_number_of_points(cb_subj1, 20)
cb_subj2 = set_number_of_points(cb_subj2, 20)
Let’s say now that we want to move the cb_subj2 (moving) so that it can be aligned with cb_subj1 (static). Here is how this is done:
from dipy.align.streamlinear import StreamlineLinearRegistration
srr = StreamlineLinearRegistration()
srm = srr.optimize(static=cb_subj1, moving=cb_subj2)
After the optimization is finished we can apply the transformation to cb_subj2.
cb_subj2_aligned = srm.transform(cb_subj2)
So let’s visualize what we did:
from dipy.viz import window, actor
ren = window.Scene()
ren.SetBackground(1, 1, 1)
bundles = [cb_subj1, cb_subj2]
colors = [window.colors.orange, window.colors.red]
for (i, bundle) in enumerate(bundles):
color = colors[i]
lines_actor = actor.streamtube(bundle, color, linewidth=0.3)
lines_actor.RotateX(-90)
lines_actor.RotateZ(90)
ren.add(lines_actor)
And now after bundle registration:
from dipy.viz import window, actor
ren = window.Scene()
ren.SetBackground(1, 1, 1)
bundles = [cb_subj1, cb_subj2_aligned]
colors = [window.colors.orange, window.colors.red]
for (i, bundle) in enumerate(bundles):
color = colors[i]
lines_actor = actor.streamtube(bundle, color, linewidth=0.3)
lines_actor.RotateX(-90)
lines_actor.RotateZ(90)
ren.add(lines_actor)
As you can see the two cingulum bundles are well aligned although they contain many streamlines of different length and shape.