EEG preprocessing with MNE
Contents
EEG preprocessing with MNE¶
Preprocessing describes the process of preparing neurophysiological data, such as the EEG data we’ll be dealing with in this chapter, for further analysis. This mainly involves removing artifacts (interference or noise due to physiological or environmental) from the recorded data, cutting out breaks in experiments, removing faulty (bad) channels and dividing the continous data into chunks centered around certain events (e.g. the presentation of a stimulus, participant’s reactions etc.). For the analysis of EEG data a few extra-steps are necessary to produce a dataset that can provide precise information about changes in neural activity or localization of involved areas, such as setting up a reference channel and applying a montage.
For examples of possible preprocessing steps see:
The PREP pipeline: standardized preprocessing for large-scale EEG analysis
Youtube: Overview of possible preprocessing steps (Mike Cohen)
and corresponding a whole set of lectures for EEG data analysis (Mike Cohen)
There is also an automated MNE pipeline that is continously improved
MNE-BIDS-PipelineSetup¶
As in the previous chapter we’ll first import our necessary libraries and the sample dataset provided by MNE.
# import necessary libraries/functions
import os
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import scipy
# this allows for interactive pop-up plots
#%matplotlib qt
# allows for rendering in output-cell
%matplotlib inline
# import mne library
import mne
from mne_bids import BIDSPath, write_raw_bids, print_dir_tree, make_report, read_raw_bids
# load some sample data, overwrite previous data
sample_data_folder = mne.datasets.sample.data_path()
sample_data_raw_file = os.path.join(sample_data_folder, 'MEG', 'sample',
'sample_audvis_raw.fif')
raw = mne.io.read_raw_fif(sample_data_raw_file, preload=True)
Opening raw data file /home/michael/mne_data/MNE-sample-data/MEG/sample/sample_audvis_raw.fif...
Read a total of 3 projection items:
PCA-v1 (1 x 102) idle
PCA-v2 (1 x 102) idle
PCA-v3 (1 x 102) idle
Range : 25800 ... 192599 = 42.956 ... 320.670 secs
Ready.
Reading 0 ... 166799 = 0.000 ... 277.714 secs...
raw.info # check the info object
| Measurement date | December 03, 2002 19:01:10 GMT |
|---|---|
| Experimenter | MEG | Participant | Unknown |
| Digitized points | 0 points |
| Good channels | 204 Gradiometers, 102 Magnetometers, 9 Stimulus, 60 EEG, 1 EOG |
| Bad channels | MEG 2443, EEG 053 |
| EOG channels | EOG 061 |
| ECG channels | Not available |
| Sampling frequency | 600.61 Hz |
| Highpass | 0.10 Hz |
| Lowpass | 172.18 Hz |
| Projections | PCA-v1 : off PCA-v2 : off PCA-v3 : off |
1.Referencing¶
As the EEG is a measurement of voltage fluctuations (differences in electric potential), we will have to naturally compare the signal measured at a specific electrode to that measured at another location.
Therefore we’ll first define a reference channel, i.e. an electrode with which the signal of electrodes of interest can be compared. This is effecitively done by substracting the signal of the reference from our measurement electrodes. When recording EEG a specific electrode or a set of electrodes should be employed that are placed in such a way that they collect ideally all the “noise” that is also influencing our measurement electrodes at the scalp, but as little as possible of the actual neural activity of interest. Common choices for the placement of reference electrodes are the earlobes or the mastoids (the bone ridges behind the ears), although sometimes central electrodes such as Cz or FCz are chosen. If we’d be interested in the signal measuered at these sites, we would have to re-reference our data.
There is a few ways to go about referencing, chek-out the MNE tutorial: Setting the EEG reference for more info.
First we’ll exclude the meg channels from our data, as we won’t be needing those for our EEG introduction. We’ll use the pick_types() fucntion, specifying which channels to keep and which to exclude by type.
raw = raw.pick_types(meg=False, eeg=True, eog=True, stim=True)
Removing projector <Projection | PCA-v1, active : False, n_channels : 102>
Removing projector <Projection | PCA-v2, active : False, n_channels : 102>
Removing projector <Projection | PCA-v3, active : False, n_channels : 102>
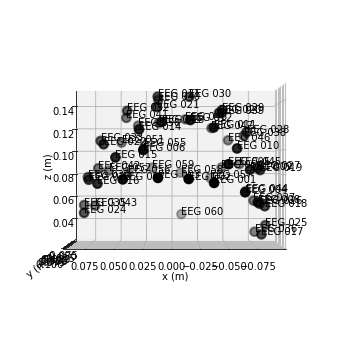
We can use use the .plot_sensors() function to see how electrodes where placed on the scalp.
raw.plot_sensors(show_names=True, kind='3d', ch_type='eeg');
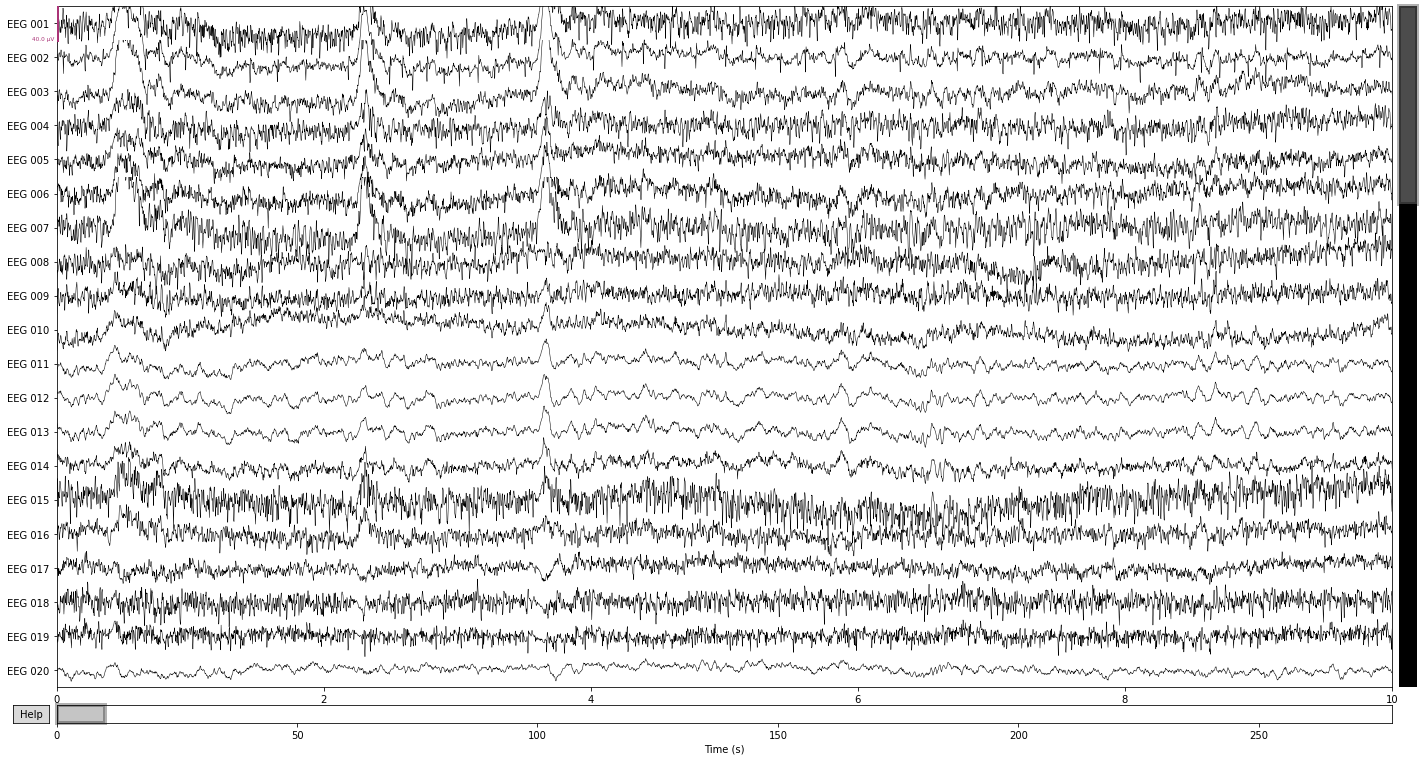
raw.plot(n_channels=61);
Using matplotlib as 2D backend.
Opening raw-browser...

Unfortunately the sample data wasn’t collected using one of the standard layouts we usually see, so it is unclear if any mastoid electrodes we’re placed. Corresponding most closely to the usual positions would be the electroed “EEG 025” and “EEG 024”, therefore we’ll see how these would function as a reference channel using the mne.set_bipolar_reference() function.
raw_bi_ref = mne.set_bipolar_reference(raw,
anode=['EEG 025'],
cathode=['EEG 024'])
EEG channel type selected for re-referencing
Creating RawArray with float64 data, n_channels=1, n_times=166800
Range : 25800 ... 192599 = 42.956 ... 320.670 secs
Ready.
Added the following bipolar channels:
EEG 025-EEG 024
and comparing the referenced data to our raw data, we’ll see that the reference channel EEG 025-EEG 024 was added in
raw_bi_ref.plot(n_channels=61);
Opening raw-browser...

With the .set_eeg_reference() function we can also apply a virtual reference channel by averaging over all electrodes by setting the parameter to ref_channels=’average’. This will overwrite our original raw data, therefore we’ll make a copy() of our raw object before assigning the data to a new variable.
# use the average of all channels as reference
raw_avg_ref = raw.copy().set_eeg_reference(ref_channels='average')
raw_avg_ref.plot();
EEG channel type selected for re-referencing
Applying average reference.
Applying a custom ('EEG',) reference.
Opening raw-browser...
We’ll be using the averaged referenced data for the next preprocessing steps, so we can get rid of the bipolar reference.
del raw_bi_ref # delete the bipolar referenced data as we won't be using it
2. Artifact detection¶
The 3 main sources of artifacts are environmental (due to power lines or electroncis), instrumentation (faulty electrodes), and biological (eye-movement, muscular activity).
For an extensive list see the MNE tutorial on artifact detection
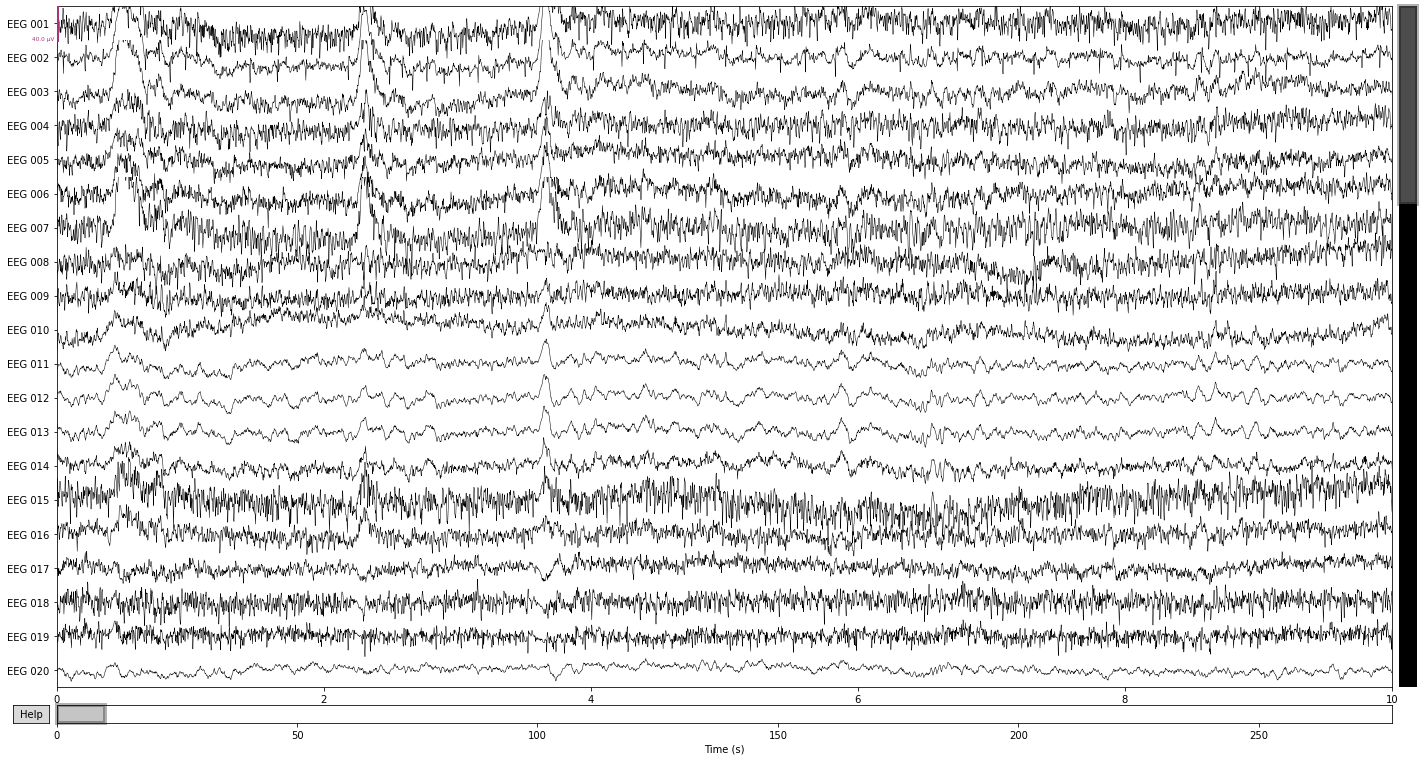
The easiest way to spot these artifacts is to simply plot the raw data if you know what you’re looking for. For example, artifacts due to eye movement will appear as a sudden step in amplitude that persist for a while in the raw data. While artifacts due to blinking will appear as a sudden spike in amplitude that is strongest in frontal electrodes and subsides with distance to the eyes. Artifacts due to muscle activity appear as sudden bursts of high frequency activity with high amplitude in the raw data.
Let’s see what we can find
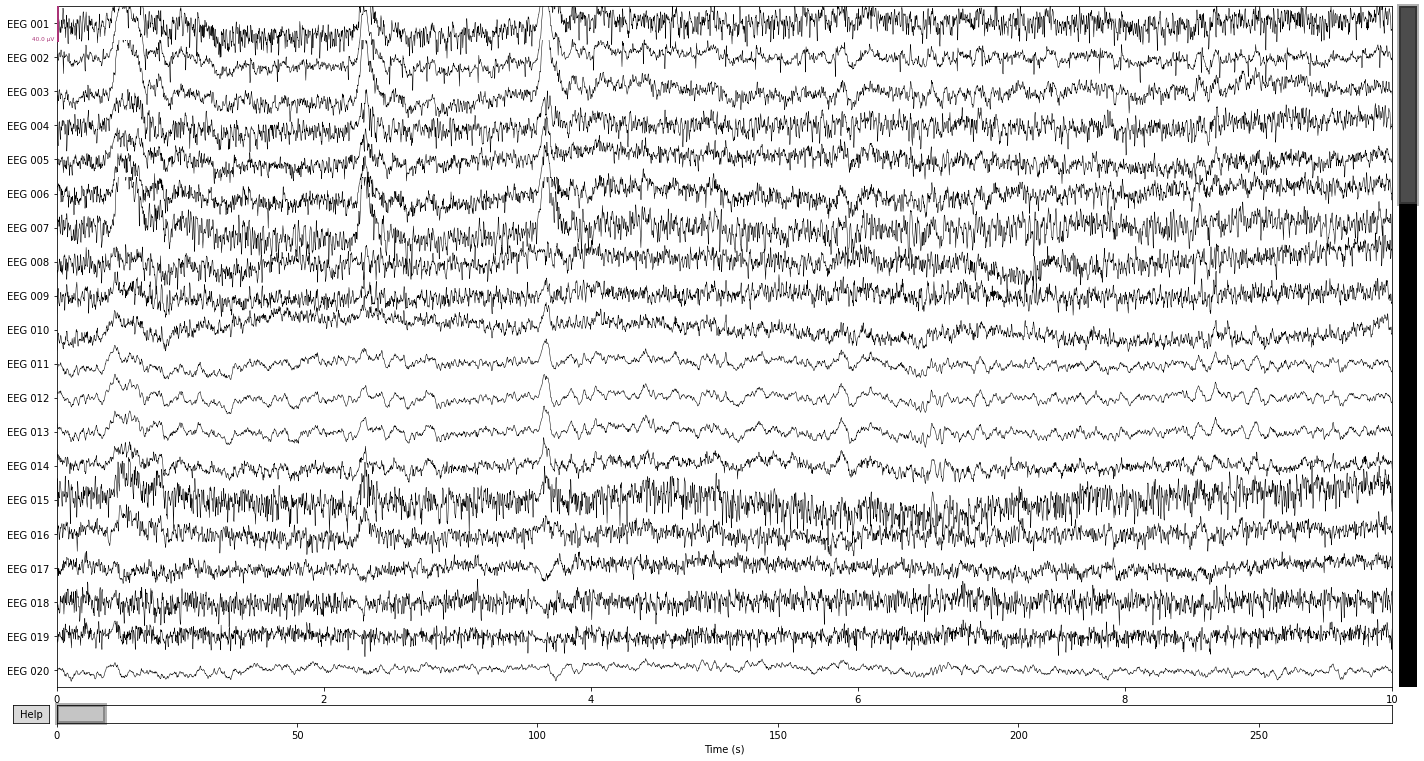
raw_avg_ref.plot();
Opening raw-browser...
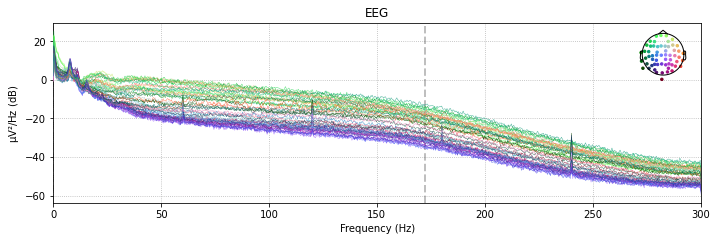
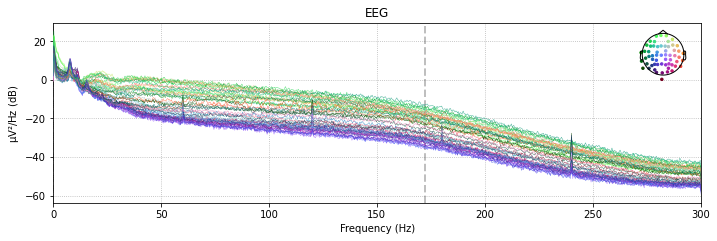
Another possibility is to plot the power spectral density (PSD, i.e. the power as µV²/Hz in dB in the frequency domain) of of our signal for each channel using the raw.plot_psd() function.
The clear spikes in power in the 60 Hz, 120 Hz etc. frequeny range are indicative of environmental interference caused by AC power lines.
raw_avg_ref.plot_psd(spatial_colors=True, picks=['eeg']);
Effective window size : 3.410 (s)
To identify artifacts automatically, we can use specific MNE functions.
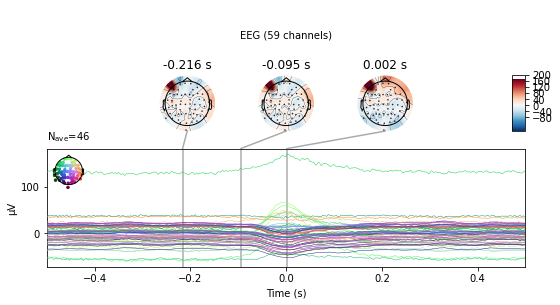
E.g. for finding eye-movemnt artifacts due to blinks MNE provides create_eog_epochs() and find_eog_events() , which we’ll use to illustrate the mean wave-form of blinks in our data:
eog_epochs = mne.preprocessing.create_eog_epochs(raw_avg_ref) # create eog epochs
eog_epochs.average().plot_joint(); # plot eog activity in source space and topography
Using EOG channel: EOG 061
EOG channel index for this subject is: [68]
Filtering the data to remove DC offset to help distinguish blinks from saccades
Setting up band-pass filter from 1 - 10 Hz
FIR filter parameters
---------------------
Designing a two-pass forward and reverse, zero-phase, non-causal bandpass filter:
- Windowed frequency-domain design (firwin2) method
- Hann window
- Lower passband edge: 1.00
- Lower transition bandwidth: 0.50 Hz (-12 dB cutoff frequency: 0.75 Hz)
- Upper passband edge: 10.00 Hz
- Upper transition bandwidth: 0.50 Hz (-12 dB cutoff frequency: 10.25 Hz)
- Filter length: 6007 samples (10.001 sec)
Now detecting blinks and generating corresponding events
Found 46 significant peaks
Number of EOG events detected: 46
Not setting metadata
46 matching events found
No baseline correction applied
Using data from preloaded Raw for 46 events and 601 original time points ...
0 bad epochs dropped
No projector specified for this dataset. Please consider the method self.add_proj.
Bad channels are most easliy identified by visual inspection: Does the signal captured by an electrode look significantly different in relation to surrounding channels? E.g. a completly flat line, high variability (i.e. appear “noisy”) or slow amplitude “drifts” over prolonged timespans. Calling the .plot() function allows us to mark channels that appear problematic by simply clicking on them, which will add them to a list object containing info on all channels marked as bad.
raw_avg_ref.plot();
Opening raw-browser...
For a more automatic approach we can identify bad channels if the contained signal exceeds a certain deviation threshold by calculating the median absolute deviation of the signal in each channel compared to the others (check robust-z-score-method for more info).
channel = raw_avg_ref.copy().pick_types(eeg=True).info['ch_names'] # get list of eeg channel names
data_ = raw_avg_ref.copy().pick_types(eeg=True).get_data() * 1e6 # * 1e6 to transform to microvolt
# calculate median absolute deviation for each channel
mad_scores =[scipy.stats.median_abs_deviation(data_[i, :], scale=1) for i in range(data_.shape[0])]
# compute z-scores for each channel
z_scores = 0.6745 * (mad_scores - np.nanmedian(mad_scores)) / scipy.stats.median_abs_deviation(mad_scores,
scale=1)
# 1/1.4826=0.6745 (scale factor for MAD for non-normal distribution)
print(z_scores)
# get channel containing outliers
bad_dev = [channel[i] for i in np.where(np.abs(z_scores) >= 3.0)[0]]
print(bad_dev)
[ 2.93167008 1.86691661 2.09310209 4.53669083 1.7094114 1.91507927
3.42109942 3.10263133 1.15765809 3.55407866 0.03090902 0.
0.07612489 0.62614561 3.10922774 1.1404617 0.14003354 1.39446589
0.32007086 -0.89047971 -0.67367991 -0.04997815 1.60603094 0.71714524
2.01475609 0.04695926 -1.01900083 -1.02329586 -0.5332095 0.12645023
-0.88577349 -1.09949559 -1.09459968 0.67719062 -0.10036744 1.20170778
0.39599687 -0.44442974 -0.83317981 -1.04410547 -0.71924608 -1.02629246
-0.36268423 -0.01897108 -0.5094786 0.95862707 -0.6745 0.57131944
-0.35042718 -0.36892057 -0.34527809 -0.52673014 -0.15169144 -0.46104639
-0.31247056 -0.20796368 -0.42393661 -0.05808648 0.47628818]
['EEG 004', 'EEG 007', 'EEG 008', 'EEG 010', 'EEG 015']
3. Artifact removal/repair¶
Next we’ll try to eliminate and or repair the previously identified artifacts with using different methods (frequency-filtering, rejecting bad channels and Independent component analysis). It is important to note that not all artifacts are problematic or should necessarily lead to complete data rejection, so we’ll try to retain as much signal as possible by removing the contaminated signal component and estimating the true signal we’d record if the specific artifacts where not present.
For a primer on how to decide which artifacts should be removed/not removed see Youtube: Signal artifacts (not) to worry about.
3.1 Filtering¶
Line noise and slow drifts are most easily dealt with by applying a filter to our data that artifically removes any activity above (highpass) or below (lowpass) a certain frequency. As the range of frequency that is actually relevant for our data or plausibly produced by neural activity is rather limited, we can for example get rid of the above identified line noise artifacts quite easily by setting a cut-off frequency (lowpass-filter) for our data somewhere below 60Hz.
There is extensive literature on and a plethora off methods to consider when it comes to eeg-filters, but for this tutorial we’ll be using the mne standard parameters. For more info on eeg-filters see the MNE: background on filtering or for a visual approach Youtube: FIR Filter Design using the Window Method.
We’ll be setting a highpass filter at 0.1hz (to get rid of slow drifts in electrode conductance over time) and a low-pass filter of 40hz (to get rid of electrical line noise).
raw_filtered = raw_avg_ref.copy().filter(l_freq=.1, h_freq=40., # lfreq = lower cut-off frequency; hfreq =upper cut-off frequency
picks=['eeg', 'eog'], # which channel to filter by type
filter_length='auto',
l_trans_bandwidth='auto',
h_trans_bandwidth='auto',
method='fir', # finite response filter; MNE default
phase='zero',
fir_window='hamming', # i.e. our "smoothing function" (MNE-default)
fir_design='firwin',
n_jobs=1)
Filtering raw data in 1 contiguous segment
Setting up band-pass filter from 0.1 - 40 Hz
FIR filter parameters
---------------------
Designing a one-pass, zero-phase, non-causal bandpass filter:
- Windowed time-domain design (firwin) method
- Hamming window with 0.0194 passband ripple and 53 dB stopband attenuation
- Lower passband edge: 0.10
- Lower transition bandwidth: 0.10 Hz (-6 dB cutoff frequency: 0.05 Hz)
- Upper passband edge: 40.00 Hz
- Upper transition bandwidth: 10.00 Hz (-6 dB cutoff frequency: 45.00 Hz)
- Filter length: 19821 samples (33.001 sec)
Comparing the filtered data in the time domain shows that we got rid of a lot of the “noisiness” present in the individual channels, as well as attentuated some of the high-frequency muscle artifacts. Ocular artifacts are still clearly present.
raw.plot();
Opening raw-browser...
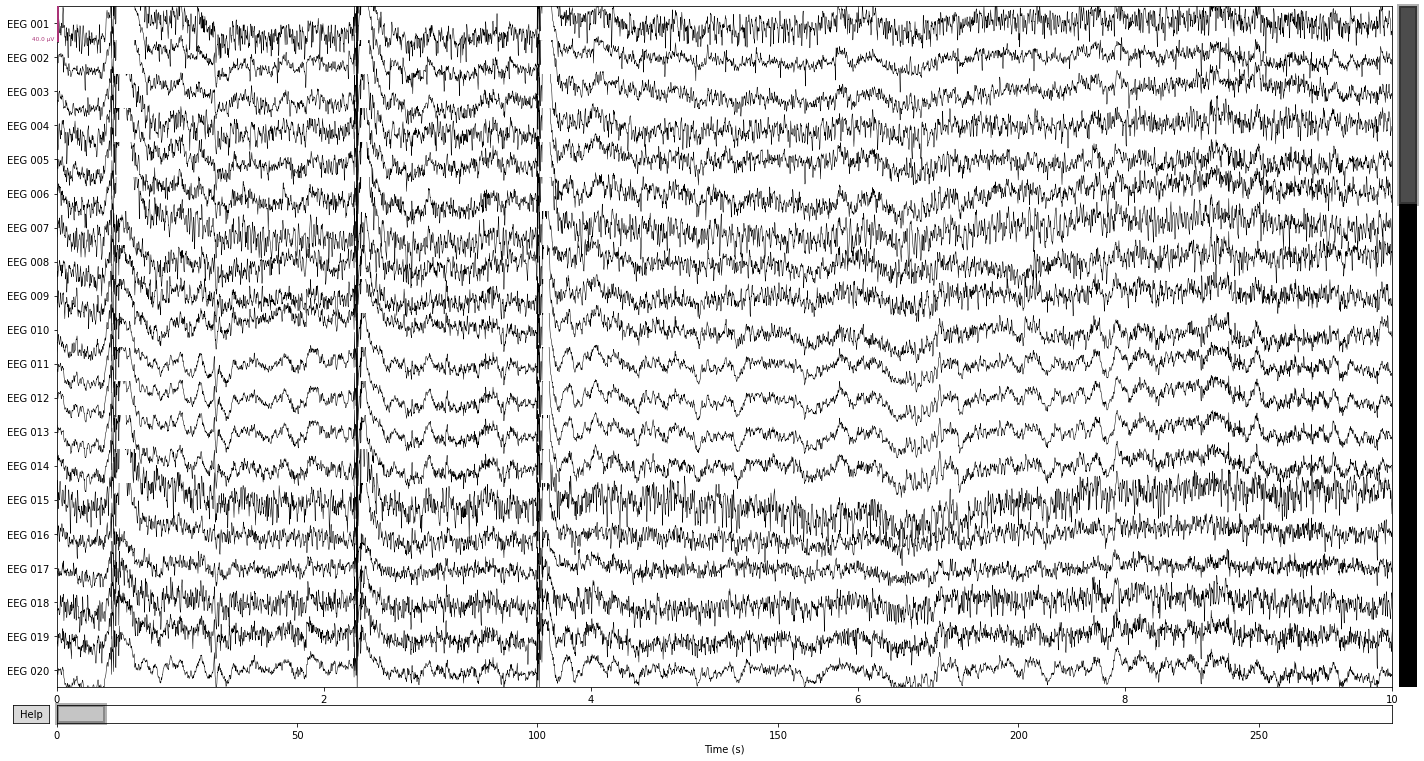
raw_filtered.plot();
Opening raw-browser...
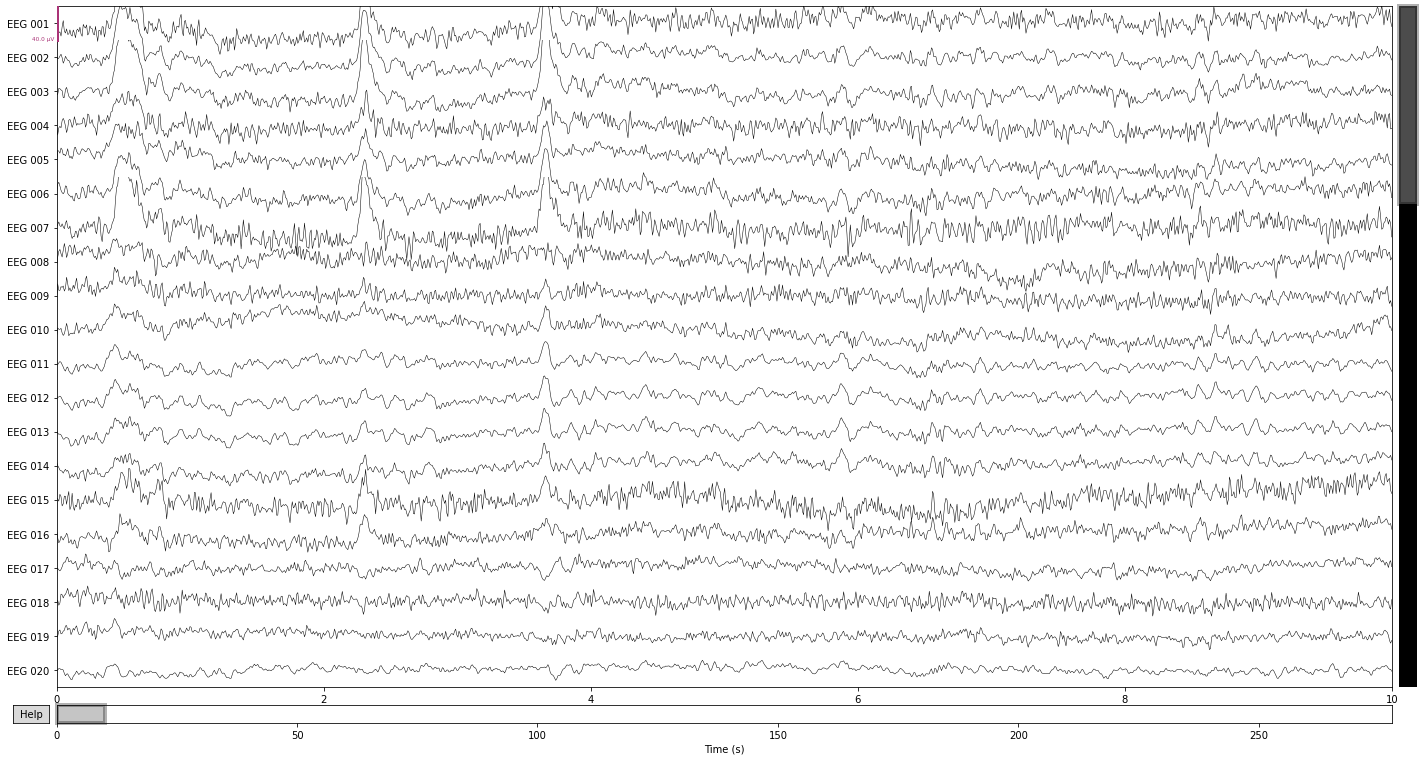
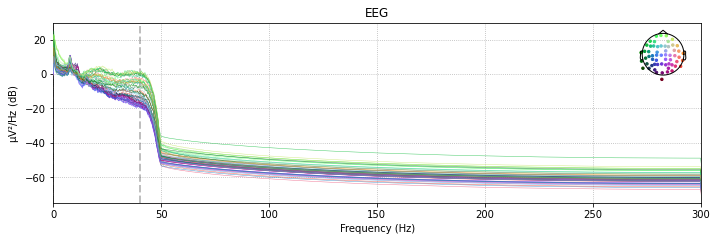
Comparing the power spectral density plots of our filtered and unfiltered data revals that frequencies above the specifed cut-off are basically eliminated from our data. The power-spectral density plot further illustrates that there is a certain drop-off range called the transition band, which in this case is about 10Hz after the specified cut-off frequency pf 40Hz
# unfiltered power spectral density (PSD)
raw_avg_ref.plot_psd(spatial_colors=True);
Effective window size : 3.410 (s)
# filtered power spectral density (PSD)
raw_filtered.plot_psd(spatial_colors=True);
Effective window size : 3.410 (s)
3.2 Interpolating bad channels¶
Let’s first take a look at the previoulsly marked bad channels for our unfiltered data again.
bad_dev
['EEG 004', 'EEG 007', 'EEG 008', 'EEG 010', 'EEG 015']
Next we calculate the median absolute deviations again, but this time for the filtered data.
channel = raw_filtered.copy().pick_types(eeg=True).info['ch_names'] # get list of eeg channel names
data_ = raw_filtered.copy().pick_types(eeg=True).get_data() * 1e6 # * 1e6 to transform to microvolt
# calculate median absolute deviation for each channel
mad_scores =[scipy.stats.median_abs_deviation(data_[i, :], scale=1) for i in range(data_.shape[0])]
# compute z-scores for each channel
z_scores = 0.6745 * (mad_scores - np.nanmedian(mad_scores)) / scipy.stats.median_abs_deviation(mad_scores,
scale=1)
# 1/1.4826=0.6745 (scale factor for MAD for non-normal distribution)
print(z_scores)
# get channel containing outliers
bad_dev = [channel[i] for i in np.where(np.abs(z_scores) >= 3.0)[0]]
print(bad_dev)
[ 2.53491522 1.73967805 2.30066055 3.08832218 1.66155918 1.85743653
3.14194962 2.46251724 0.90603823 2.26484445 0.06479951 0.29247788
0.3325463 0.70652085 2.51787841 0.89403503 0. 0.6745
-0.35824365 -0.8605855 -0.59368432 -0.37479054 0.91453675 0.47206722
2.17453196 -0.48878472 -1.20579555 -1.04112896 -0.72032546 0.16183855
-0.85172137 -1.05013466 -1.09402637 0.03657005 -0.04724789 1.38467332
-0.13037815 -0.68966154 -0.91377994 -0.95780618 -0.82304069 -1.00630492
-0.32368758 0.08028723 -0.43569248 0.97852603 -0.60128033 0.40168626
-0.35229997 -0.32971686 -0.26989682 -0.55193517 0.05454042 -0.25843797
-0.10949953 -0.04371482 -0.23934103 0.13879019 0.16710858]
['EEG 004', 'EEG 007']
Now we see that only 2 out of 5 channels are considered to be outliers. So it appears that our filter got rid of some of the problematic noise in our channels already. We'll check if there is already info about bad channels in the metadata of our raw object, that the experimenters may have already provide. Information on which channels are bad is stored in the .info object.
raw_filtered.info['bads']
[]
Adding our outlier channels to the list of “bad” channesl basically means that we declare that these channels should not be considered for further analysis.
As .info[‘bads’] is a regular python list we can edit it in a few simple ways, e.g. let’s say electrode EEG 007 would look wildly out of place compared to the signal in the surrounding electrodes. Now e.g. we can add entries using .append() to our list
raw_filtered.info['bads'].append('EEG 007') # add bad channel
raw_filtered.info['bads']
['EEG 007']
remove entries via .pop
raw_filtered.info['bads'].pop(-1) # remove last entry
raw_filtered.info['bads']
[]
and add multiple values to our list of bads or even completly replace our list of bad channels.
old_bads = raw_filtered.info['bads'] # create variable containing original bad channels
new_bads = ['EEG 008', 'EEG 009'] # create list of channels to add
# overwrite the whole list
raw_filtered.info['bads'] = new_bads
print(raw_filtered.info['bads'])
# or combine old an new list of bad channels
raw_filtered.info['bads'] = old_bads + new_bads
print(raw_filtered.info['bads'])
['EEG 008', 'EEG 009']
['EEG 008', 'EEG 009']
Let's empty our list of bad channels for now
raw_filtered.info['bads'] = [] # set empty list
print(raw_filtered.info['bads'])
[]
and add the outlier channels we’ve identified above
raw_filtered.info['bads'] = bad_dev
print(raw_filtered.info['bads'])
['EEG 004', 'EEG 007']
taking a look at the "Bad channels" row of the .info reveals that the marked channels are now part of the raw objects metadata.
raw_filtered.info
| Measurement date | December 03, 2002 19:01:10 GMT |
|---|---|
| Experimenter | MEG | Participant | Unknown |
| Digitized points | 0 points |
| Good channels | 9 Stimulus, 59 EEG, 1 EOG |
| Bad channels | EEG 004, EEG 007 |
| EOG channels | EOG 061 |
| ECG channels | Not available |
| Sampling frequency | 600.61 Hz |
| Highpass | 0.10 Hz |
| Lowpass | 40.00 Hz |
Interpolation¶
Now that we know which channels are problematic, we can estimate their actual signal given the signal of the surrounding electrodes via the .interpolate_bads() fucntion, as with the relatively poor spatial resolution it is highly unklikey that one electrode would have picked up a signal that is not also to a to lesser degree present in the surrounding electrodes. This concept is illustrated well in the visualizatio of the topopgraphic spread of evoked potentials here. See the MNE tutorial: interpolate bad channels for more on the implementation and the therein cited papers for the technical information.
When to interpolate or drop bad channels should be decided on an individual basis. In general, if the signal picked up is consistently bad/noisy and might influence the overall quality of the data the channel can be interpolated. If there are only single “ariftact events in” the channel it’s best to keep the channel and later on exclude the epoch containing the artifact. For automatization purposes you’ll of course have to make an a priori decison on what levels of noise e.g. you’re willing to accept.
print(raw_filtered.info['bads'])
['EEG 004', 'EEG 007']
For ilustrative purposes we’ll interpolate the channels we’ve identified as outliners above and compare the data before and after interpolation.
interp_ = raw_filtered.copy().interpolate_bads(reset_bads=False) # copy() as this would modify the raw object in place
interp_.plot();
Interpolating bad channels
Automatic origin fit: head of radius 91.0 mm
Computing interpolation matrix from 57 sensor positions
Interpolating 2 sensors
Opening raw-browser...
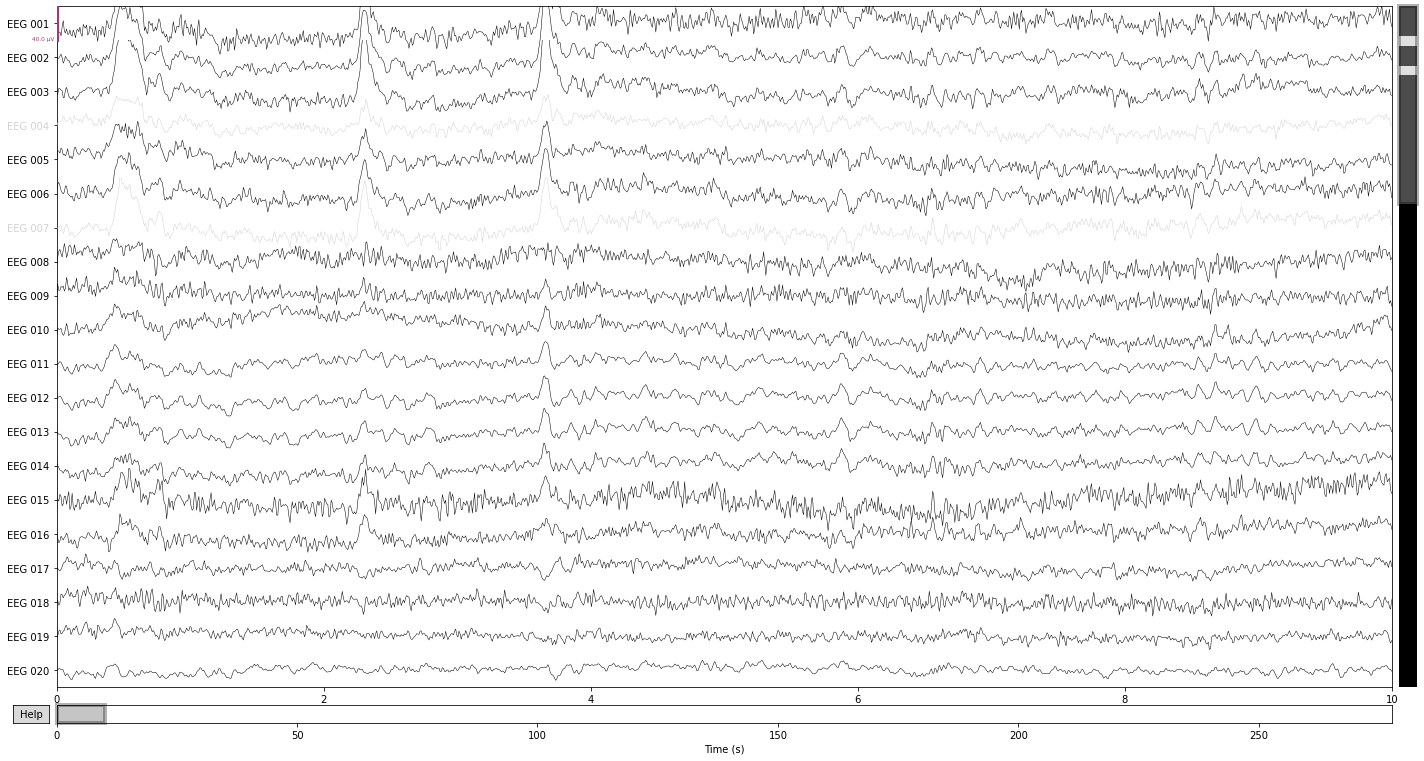
raw_filtered.plot();
Opening raw-browser...
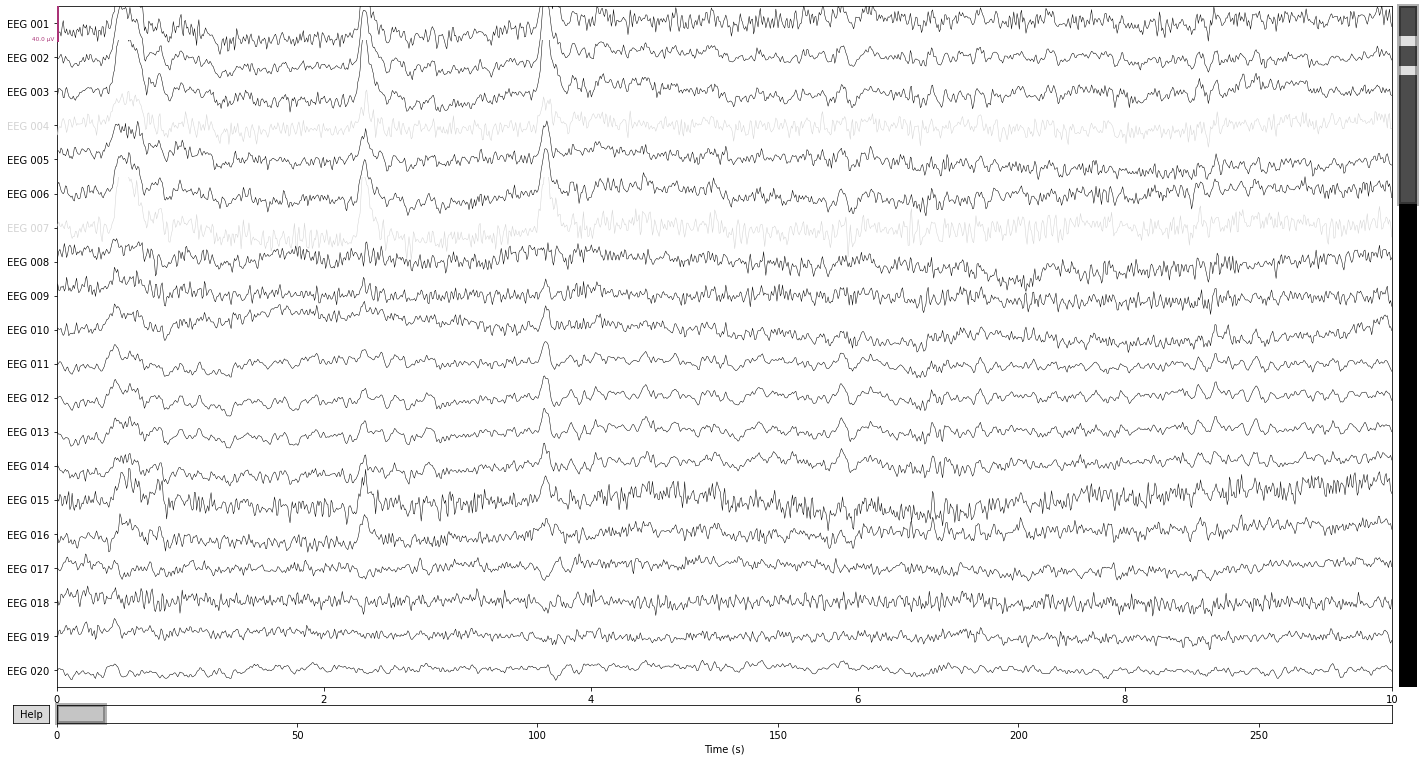
We see a reduction in the amplitude of the high frequency components in the channels "EEG 004" and "EEG 007", as well as an general "reshaping" of the data as a composition of activity in the surrounding channels. A prominent example would be the change in wave-form for the first blink-artifact in channel "EEG 004".
Let’s apply this to our data and reset our bad channels, so that they’ll not be excluded from further analysis anymore.
raw_filtered.interpolate_bads(reset_bads=True)
Interpolating bad channels
Automatic origin fit: head of radius 91.0 mm
Computing interpolation matrix from 57 sensor positions
Interpolating 2 sensors
| Measurement date | December 03, 2002 19:01:10 GMT |
|---|---|
| Experimenter | MEG | Participant | Unknown |
| Digitized points | 0 points |
| Good channels | 9 Stimulus, 59 EEG, 1 EOG |
| Bad channels | None |
| EOG channels | EOG 061 |
| ECG channels | Not available |
| Sampling frequency | 600.61 Hz |
| Highpass | 0.10 Hz |
| Lowpass | 40.00 Hz |
| Filenames | sample_audvis_raw.fif |
| Duration | 00:04:37 (HH:MM:SS) |
del interp_ # delete to free up space
3.3 Independent component analysis (ICA)¶
One of the most common and effetive tools for artifact detection and removal is the Independent component analysis, which we’ll use to exclude our occular artifacts from the data in the next step
In brief: ICA is a technique for signal processing that separates a signal into a specified number of linearly mixed sources. For the preprocessing of EEG data this is used to find statistically independet sources of signal variability present in our n_channel dimensional data. EEG artifacts are usually strong sources of variability as they show higher amplitude than would be expected for sources of neural activity and generally appear more consistent than fluctuating neural activity, best illustrated by occular artifacts, and can therefore be easily identified via ICA.
An ICA is performed in multiply steps:
Specify the ICA algorithm/paramertes:
n_components = the number of components we want to decompose our signal in. The more components one includes the more accurate the ICA solution becomes, i.e. the finer grained your sources of variability will be identified in the specific components.
max_iter = the number of iterations for approximation (see Wikipedia: iterative processes for more)
random_state = identifier for the initial value/decomposition matrix used (as ICA is non-deterministic this is necessary to reproduce the same output when repeating the ICA)
method = the ICA algorithm to use, defaults to “fastica”. Choice of algorithm usually boils down to computational speed vs. maximization of information (see the MNE API: preprocessing.ICA for more information)
Fit the ICA to the data/Identify ICA components
visualize your component solution, i.e artifact detection
for an introductionary tutorials to identifying ICA components in eeg see ICLabel Tutorial: EEG Independent Component Labeling
Specify which components should be removed from the data
Reconstructing the Signal, i.e. apply the ICA solution with the components containing artifacts excluded from the data
Further reading
For more theory on the ICA and how it’s used in MNE etc. see the MNE tutorial: artifact correction via ica and Scikit-learn example: ica blind source separation
For more general explanations on ICA for EEG data, what to look for, which artifacts to include etc., see the video Independent components analysis for removing artifacts by Mike X Cohen or the video series on ICA applied to EEG time series by Arnaud Delorme.
For this tutorial we’ll be excluding ICA components by hand (or eye), but to remove researcher bias and allow for analysis of larger sample sizes we could also employ ica templates based on certain common artifacts and automate this process. See MNE tutorial: selecting ica components using template matching for more info.
1. Specify the ICA algorithm/paramertes:
ica = mne.preprocessing.ICA(n_components=20,
random_state=7,
max_iter='auto',
method='infomax') # set-up ICA parameters
2. Fit the ICA to the data/Identify ICA components
ICA_solution = ica.fit(raw_filtered) # fit the ICA to our data
Fitting ICA to data using 59 channels (please be patient, this may take a while)
Selecting by number: 20 components
Fitting ICA took 16.7s.
Now we have a number of ways for visualizing the identified sources of variability.
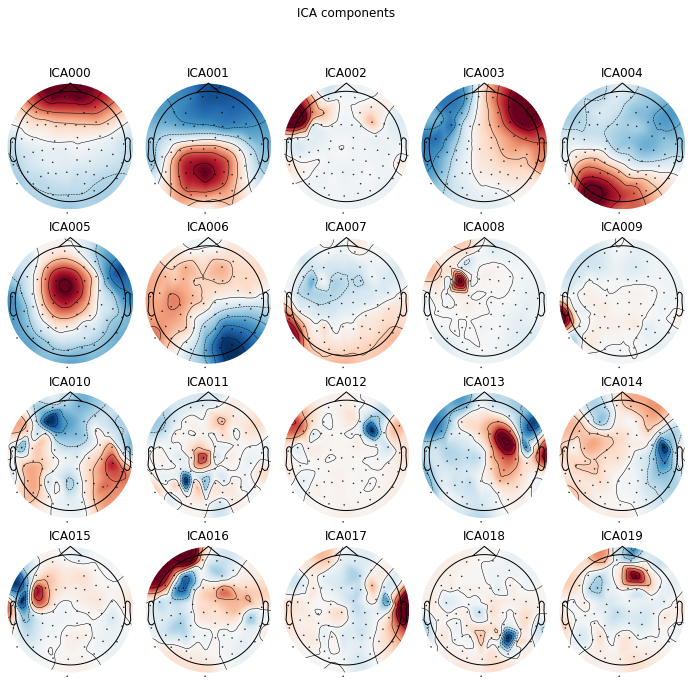
We can plot the ICA componets as a projection on the sensor topography, to see where the variability in our signal is located in sensor space. E.g. occular activiy should be located over frontal electrodes, like in component ICA 000 and component ICA 003
ica.plot_components(picks=range(0, 20)); # visualize our components
Another way to visualize our ICA solution and one of the easiest ways to understand what patterns of variability in our data an ICA component captures, is to visualize the components in source space, i.e. how do the components represent latent sources of signal variability over time. See MNE API: plot_sources() for more info.
ica.plot_sources(raw_filtered);
Creating RawArray with float64 data, n_channels=21, n_times=166800
Range : 25800 ... 192599 = 42.956 ... 320.670 secs
Ready.
Opening ica-browser...
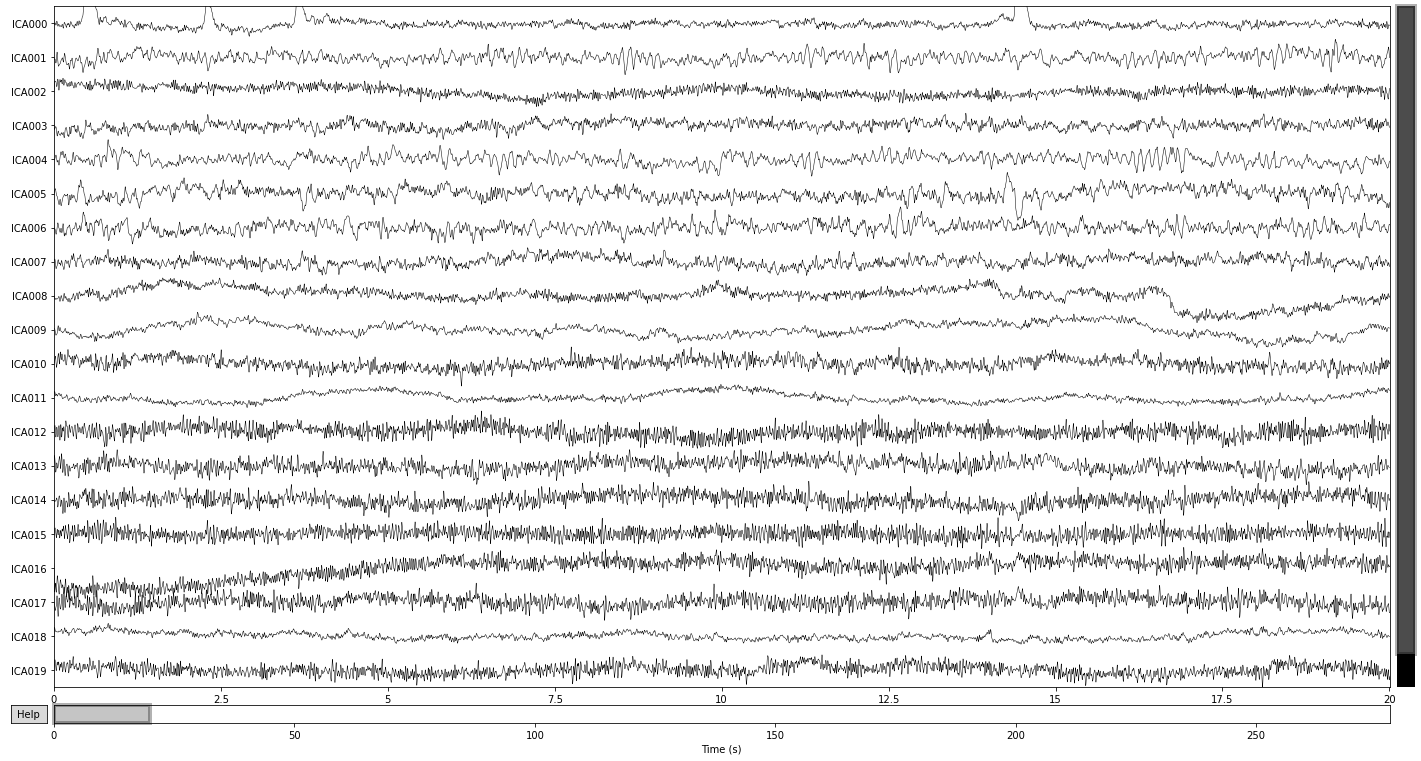
You can scroll through the plot_sources() output (if opened via binder or jupyter notebooks/lab) and compare it with the topographical map above, to see if you can spot some more artifcats or if you can identify genuine sources of neural activity.
Here we see that the first component (ICA 000) appears to capture our blink artifacts, while the later parts of ICA 003 appears to be indicative of horizontal eye movement. The topographical location of these artifacts in the plot above points towards the same intepretation. ICA 11 and ICA 18 additionaly appear to capture some weird artifacts, possibly due to channel noise or electrical interference.
To visualize what would happen to our signal if we were to extract these components, we can use the plot_overlay() function and pass the problematic ica components by their index as arguments.
ica.plot_overlay(raw_filtered, exclude=[0, 3]);
Applying ICA to Raw instance
Transforming to ICA space (20 components)
Zeroing out 2 ICA components
Projecting back using 59 PCA components
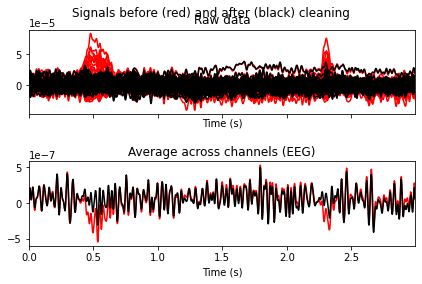
And it appears that the exclusion of the two components results in the elimination of the blink artifacts.
Note of caution: It’s generally advised not to exclude components if you’re not certain that they may contain artifacts. Adjustments for artifcats that are only present in a small subset of all events (e.g. presented stimuli) can still be made later by excluding the affected epochs. So we’ll stick with the exclusion of these 2 components for now.
3. Specify which components you want to remove from the data
We’ll add the components we want to exclude from our data to the ica.exlude object (which can be done the same way as we did above withe raw.info[bads] list), create a copy of our filtered data (as to not modify it in place) and apply the ica solution.
# apply ica to data
ica.exclude = [0, 3]
4. Reconstructing the Signal
reconst_sig = raw_filtered.copy().pick_types(eeg=True, exclude='bads')
ica.apply(reconst_sig)
Applying ICA to Raw instance
Transforming to ICA space (20 components)
Zeroing out 2 ICA components
Projecting back using 59 PCA components
| Measurement date | December 03, 2002 19:01:10 GMT |
|---|---|
| Experimenter | MEG | Participant | Unknown |
| Digitized points | 0 points |
| Good channels | 59 EEG |
| Bad channels | None |
| EOG channels | Not available |
| ECG channels | Not available |
| Sampling frequency | 600.61 Hz |
| Highpass | 0.10 Hz |
| Lowpass | 40.00 Hz |
| Filenames | sample_audvis_raw.fif |
| Duration | 00:04:37 (HH:MM:SS) |
And lastly comparing our ICA reconstructed signal to the filtered data, it seems that we got rid of most ocular artifacts.
raw_filtered.plot();
Opening raw-browser...
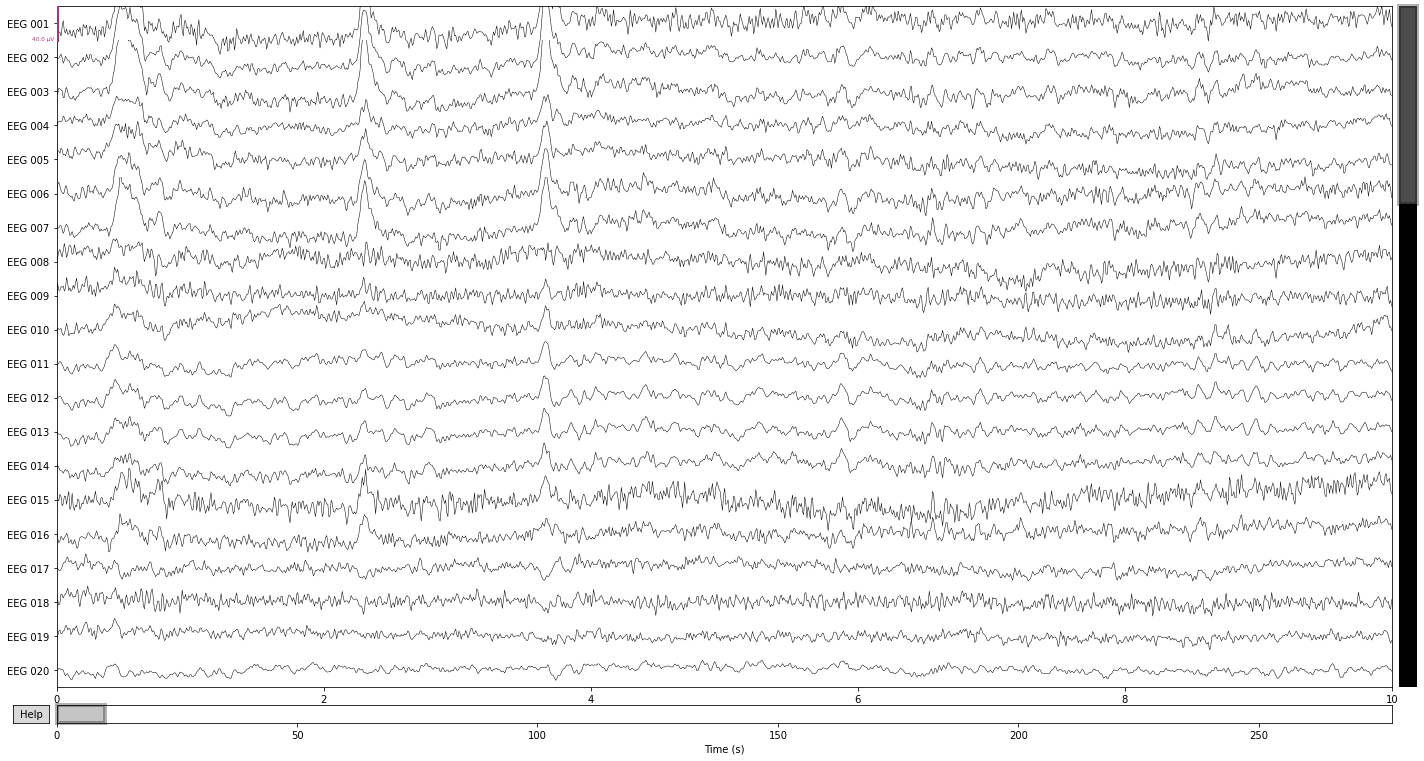
reconst_sig.plot();
Opening raw-browser...
To free up space we get rid of the filtered data
del raw_filtered
Now we can save the preprocessed data for further processing.
Let’s first get our paths in order.
homedir = os.path.expanduser("~") # find home diretory
output_path = (homedir + str(os.sep) + 'msc_05_example_bids_dataset' +
str(os.sep) + 'sub-test' + str(os.sep) + 'ses-001' + str(os.sep) + 'meg')
print(output_path)
/home/michael/msc_05_example_bids_dataset/sub-test/ses-001/meg
and save again using the raw.save() function.**
reconst_sig.save(output_path + ((os.sep) +
'sub-test_ses-001_sample_audiovis_eeg_data_preprocessed.fif'), # the filename
picks=['eeg', 'eog', 'stim'], # the channels to pick (could also be single channels)
overwrite=True) # checks if data is already present and overwrites if true
Writing /home/michael/msc_05_example_bids_dataset/sub-test/ses-001/meg/sub-test_ses-001_sample_audiovis_eeg_data_preprocessed.fif
Closing /home/michael/msc_05_example_bids_dataset/sub-test/ses-001/meg/sub-test_ses-001_sample_audiovis_eeg_data_preprocessed.fif
[done]
/tmp/ipykernel_29153/2232610041.py:4: RuntimeWarning: This filename (/home/michael/msc_05_example_bids_dataset/sub-test/ses-001/meg/sub-test_ses-001_sample_audiovis_eeg_data_preprocessed.fif) does not conform to MNE naming conventions. All raw files should end with raw.fif, raw_sss.fif, raw_tsss.fif, _meg.fif, _eeg.fif, _ieeg.fif, raw.fif.gz, raw_sss.fif.gz, raw_tsss.fif.gz, _meg.fif.gz, _eeg.fif.gz or _ieeg.fif.gz
overwrite=True) # checks if data is already present and overwrites if true
Other techniques for artifact detection/repair?
For an overview of other techniques for preprocessing you can follow these MNE tutorials:
MNE tutorial: Repairing artifacts with Signal-space projection (SSP)
MNE tutorial: Signal-space separation (SSS) and Maxwell filtering
MNE tutorial: Surface Laplacian for cleaning, topoplogical localization, and connectivity
4. Epoching¶
Epochs¶
Epochs represent chunks of continous eeg data time-locked to certain events or periods of activity (e.g. experimental blocks). They are usually equal length and should contain enough time before an event to allow for baseline correction and enough time after the stimulus to catch all possible activity (evoked/event-related potentials or changes in frequency band) of interest for later analysis.
The mne.Epochs objects can be treated the same as the previous raw objects in a number of ways, including the .info() manipulations we
To create our epochs we need two things: - raw or preprocessed data - events
For more info on the Epochs data structure see the MNE tutorial: The Epochs data structure: discontinuous data
Events¶
Events in the context of this tutorial are flags indicating that at a certain time the presentation of a stimulus or a participant’s reaction has occured. Event IDs indicate what kind of condition was recorded, usually they are stored as simple integers.
Information on what kind of stimulus/reaction was recorded is in general stored in the “Stim” channels or the metadata of the raw object (check raw.info[‘events’]). Otherwise, if the Data is organized in the BIDS format, you can check the “_events.tsv” file in the subject folder and for the possible descriptions of the contained event-identifiers the “dataset_description.json” or the “README.txt”. Some systems save events in a separate annotation file (e.g. eeglab set files), for which mne provides a dedicated function to convert these files to an event array. See MNE tutorial: Parsing events from raw data for more info.
reconst_sig.info['events'] # check if info on events is contained in raw object
[{'channels': array([307, 308, 309, 310, 311, 312, 313, 314, 315], dtype=int32),
'list': array([ 16422, 0, 64, ..., 168680, 32, 0], dtype=int32)}]
raw.info['ch_names'] # see if stim_channel are found in the raw object
['STI 001',
'STI 002',
'STI 003',
'STI 004',
'STI 005',
'STI 006',
'STI 014',
'STI 015',
'STI 016',
'EEG 001',
'EEG 002',
'EEG 003',
'EEG 004',
'EEG 005',
'EEG 006',
'EEG 007',
'EEG 008',
'EEG 009',
'EEG 010',
'EEG 011',
'EEG 012',
'EEG 013',
'EEG 014',
'EEG 015',
'EEG 016',
'EEG 017',
'EEG 018',
'EEG 019',
'EEG 020',
'EEG 021',
'EEG 022',
'EEG 023',
'EEG 024',
'EEG 025',
'EEG 026',
'EEG 027',
'EEG 028',
'EEG 029',
'EEG 030',
'EEG 031',
'EEG 032',
'EEG 033',
'EEG 034',
'EEG 035',
'EEG 036',
'EEG 037',
'EEG 038',
'EEG 039',
'EEG 040',
'EEG 041',
'EEG 042',
'EEG 043',
'EEG 044',
'EEG 045',
'EEG 046',
'EEG 047',
'EEG 048',
'EEG 049',
'EEG 050',
'EEG 051',
'EEG 052',
'EEG 054',
'EEG 055',
'EEG 056',
'EEG 057',
'EEG 058',
'EEG 059',
'EEG 060',
'EOG 061']
4.1 finding/renaming events¶
To find the events in the raw file we can usually use find_events() function on our raw object. This function automatically checks if there are Stim channel present in the data. Stimulus channel do not collect EEG data, but the triggers associated with events that an experiment may contain.
events = mne.find_events(raw)
320 events found
Event IDs: [ 1 2 3 4 5 32]
We ca visualize these stimulus channel using the .pick_types() function on our raw when we sett the “stim” parameter to true.
raw.copy().pick_types(meg=False, stim=True).plot(); # copy as to not modify our data in place
Opening raw-browser...

Looking at these channels it becomes obvious that “STI 014” contains all relevant events contained in the other stimuli channel and encodes them by variations in amplitude. Therefore explicitly picking the events from this channel leads to the same result as the function above.
Looking at the other stim channels reveals that they each contain only a single kind of event. E.g. “STI 002” contains only the event with the ID “5”
events = mne.find_events(raw, stim_channel='STI 002')
146 events found
Event IDs: [5]
Let’s get all events
events = mne.find_events(raw, stim_channel='STI 014')
320 events found
Event IDs: [ 1 2 3 4 5 32]
In the MNE: Epochs tutorial, a list of labels for the events in the sample data corresponding to our event_id’s is provided, which we can use to make our data a little more readable.
event_id = {'Auditory/Left': 1, 'Auditory/Right': 2,
'Visual/Left': 3, 'Visual/Right': 4,
'smiley': 5, 'button': 32}
We can further use these descriptions when visulaizing our events using the plot_events() function
#Specify colors for events for the plot legend
color = {1: 'green', 2: 'yellow', 3: 'red', 4: 'c', 5: 'black', 32: 'blue'}
# Plot the events to get an idea of the paradigm
mne.viz.plot_events(events,
raw.info['sfreq'], # sampling frequency
raw.first_samp, # starting point of plot (first sample)
color=color, # the color dict specified above
event_id=event_id, # our event dictionary
equal_spacing=True);
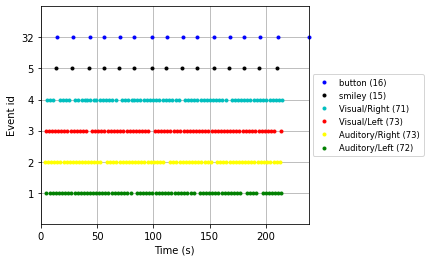
With this information we can finally create our epochs object using the mne.Epochs() constructor function
Baseline correction will be automatically applied given the intervall between tmin (epoch start) and t = 0 (i.e. the relevant event) of specified epochs, but can be specified by adding the baseline parameter to the mne.Epochs() constructor. Baseline correction is applied to each channel and epoch respetively by calculating the mean for the baseline period and substracting this mean from the signal of the entire epoch.
# like with raw objects data is not automatically loaded into memory, therefore we set preload=True
epochs = mne.Epochs(reconst_sig,
events,
picks=['eeg'],
tmin=-0.3, # start of epoch relative to event in seconds
tmax=0.7, # end of epoch relative to event
#baseline=(-0.3,0),
preload=True)
Not setting metadata
320 matching events found
Setting baseline interval to [-0.2996928197375818, 0.0] sec
Applying baseline correction (mode: mean)
0 projection items activated
Using data from preloaded Raw for 320 events and 601 original time points ...
0 bad epochs dropped
epochs.info
| Measurement date | December 03, 2002 19:01:10 GMT |
|---|---|
| Experimenter | MEG | Participant | Unknown |
| Digitized points | 0 points |
| Good channels | 59 EEG |
| Bad channels | None |
| EOG channels | Not available |
| ECG channels | Not available |
| Sampling frequency | 600.61 Hz |
| Highpass | 0.10 Hz |
| Lowpass | 40.00 Hz |
print(epochs)
<Epochs | 320 events (all good), -0.299693 - 0.699283 sec, baseline -0.299693 – 0 sec, ~89.5 MB, data loaded,
'1': 72
'2': 73
'3': 73
'4': 71
'5': 15
'32': 16>
Let's recreate our dictionary containing the explicit event names and add our event dict to the event object, so that we can later access data based on these labels
event_dict = {'auditory/left': 1, 'auditory/right': 2, 'visual/left': 3,
'visual/right': 4, 'face': 5, 'buttonpress': 32}
epochs.event_id = event_dict
print(epochs)
print(epochs.event_id)
<Epochs | 320 events (all good), -0.299693 - 0.699283 sec, baseline -0.299693 – 0 sec, ~89.5 MB, data loaded,
'auditory/left': 72
'auditory/right': 73
'visual/left': 73
'visual/right': 71
'face': 15
'buttonpress': 16>
{'auditory/left': 1, 'auditory/right': 2, 'visual/left': 3, 'visual/right': 4, 'face': 5, 'buttonpress': 32}
We can visualize epochs in the same way we visualized raw data previously
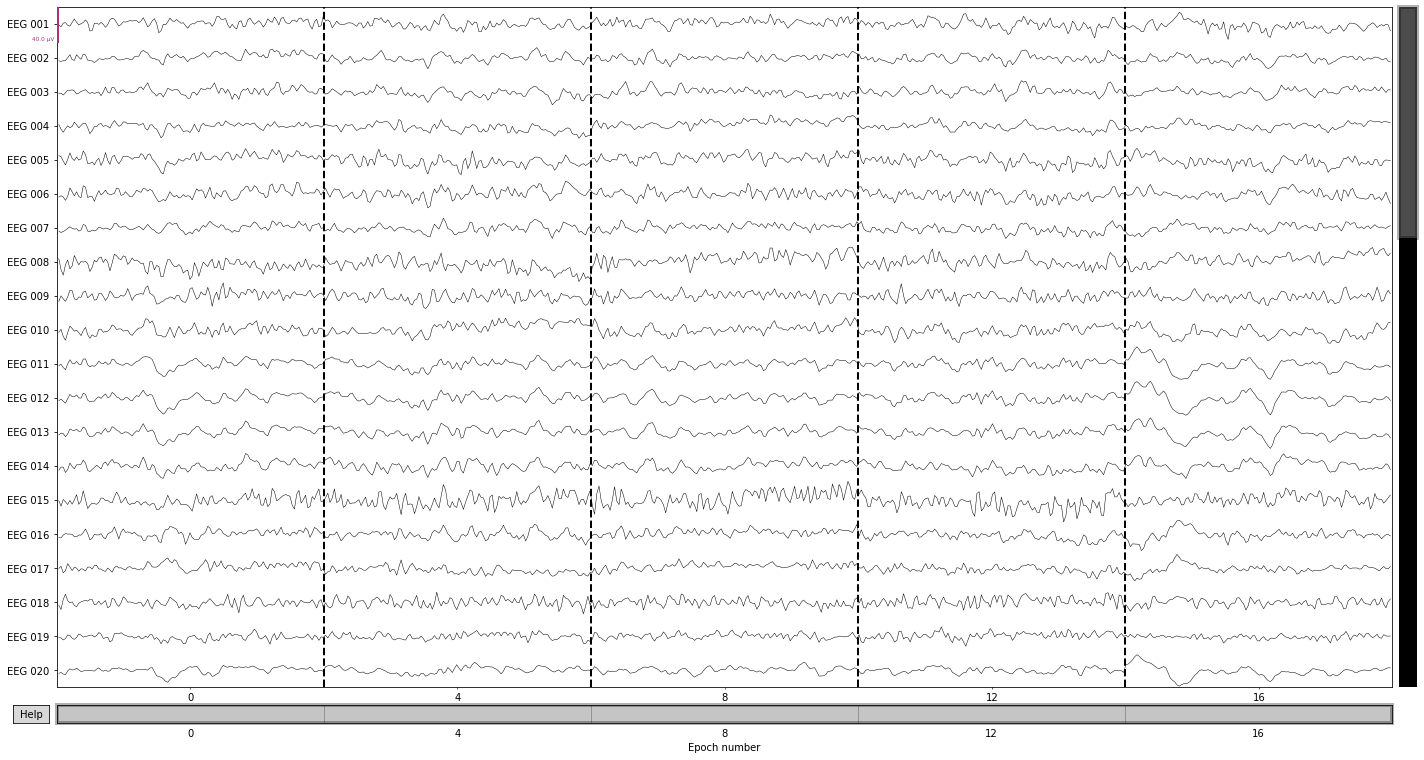
epochs.plot(n_epochs=5); # pick first 5 epochs
Opening epochs-browser...
epochs.plot(events=events); #or plot all by event type
You seem to have overlapping epochs. Some event lines may be duplicated in the plot.
Opening epochs-browser...
We can then select epochs based on the events they are centered around in a number of ways.
epochs.event_id # recall what our events are
{'auditory/left': 1,
'auditory/right': 2,
'visual/left': 3,
'visual/right': 4,
'face': 5,
'buttonpress': 32}
Select by a specific group of events (MNE treats the "/" character as a string separator, so we can explicitly call only auditory epochs etc.)
epochs['auditory'] # epochs centered around presentation of auditory stimulus
| Number of events | 145 |
|---|---|
| Events | auditory/left: 72 auditory/right: 73 |
| Time range | -0.300 – 0.699 sec |
| Baseline | -0.300 – 0.000 sec |
epochs['visual'] # epochs centered around presentation of visual stimulus
| Number of events | 144 |
|---|---|
| Events | visual/left: 73 visual/right: 71 |
| Time range | -0.300 – 0.699 sec |
| Baseline | -0.300 – 0.000 sec |
epochs['right'] # subselect only stimuli presented on the right side
| Number of events | 144 |
|---|---|
| Events | auditory/right: 73 visual/right: 71 |
| Time range | -0.300 – 0.699 sec |
| Baseline | -0.300 – 0.000 sec |
select by multiple tags (i.e select all epochs containing either "right" or "auditory")
epochs[['right', 'auditory']]
| Number of events | 216 |
|---|---|
| Events | auditory/left: 72 auditory/right: 73 visual/right: 71 |
| Time range | -0.300 – 0.699 sec |
| Baseline | -0.300 – 0.000 sec |
or by using the explicit label of the specific event
# using explicit label
epochs[['auditory/right']]
| Number of events | 73 |
|---|---|
| Events | auditory/right: 73 |
| Time range | -0.300 – 0.699 sec |
| Baseline | -0.300 – 0.000 sec |
# using explicit label
epochs[['auditory/left']]
| Number of events | 72 |
|---|---|
| Events | auditory/left: 72 |
| Time range | -0.300 – 0.699 sec |
| Baseline | -0.300 – 0.000 sec |
We can further select epochs by their index using list comprehensions.
print(epochs[:10]) # first 10 epochs
print(epochs[:10:2]) # epochs 1, 3, 5, 7, 9; i.e [start:stop:step-size]
print(epochs['auditory'][:10:2]) # or select explicitly
print(epochs['auditory'][[0, 2, 4, 6, 8]]) # or select explicitly
epochs['auditory'][[0, 2, 4, 6, 8]].plot();
<Epochs | 10 events (all good), -0.299693 - 0.699283 sec, baseline -0.299693 – 0 sec, ~5.7 MB, data loaded,
'auditory/left': 2
'auditory/right': 3
'visual/left': 3
'visual/right': 2>
<Epochs | 5 events (all good), -0.299693 - 0.699283 sec, baseline -0.299693 – 0 sec, ~4.3 MB, data loaded,
'auditory/left': 2
'auditory/right': 3>
<Epochs | 5 events (all good), -0.299693 - 0.699283 sec, baseline -0.299693 – 0 sec, ~4.3 MB, data loaded,
'auditory/right': 5>
<Epochs | 5 events (all good), -0.299693 - 0.699283 sec, baseline -0.299693 – 0 sec, ~4.3 MB, data loaded,
'auditory/right': 5>
Opening epochs-browser...
and access the contained data again via the get_data() function, which returns a np.array of the shape (number of epochs, number of channels, number of time-points)
print(epochs.get_data()) # array (n_epochs, n_channels, n_times)
epochs.get_data().shape
[[[-1.53682615e-07 1.76059818e-07 4.55425791e-08 ... 4.66550977e-06
6.94681262e-06 8.74132001e-06]
[-4.28382745e-06 -3.49376566e-06 -2.85756692e-06 ... 5.60403187e-06
5.43679679e-06 5.40910467e-06]
[-4.85437478e-06 -4.64429674e-06 -4.16165507e-06 ... 2.27513486e-06
1.89663829e-06 1.79428859e-06]
...
[ 3.35085006e-06 3.47503013e-06 3.59880996e-06 ... -2.00678158e-08
1.43032391e-07 1.75713615e-07]
[ 1.31399230e-06 1.59594277e-06 1.87315172e-06 ... 1.97230798e-06
2.16159788e-06 2.08545430e-06]
[ 7.25402012e-07 1.04189705e-06 1.34003488e-06 ... 2.82710672e-06
3.41396440e-06 3.85433967e-06]]
[[ 4.64551860e-06 3.90649334e-06 3.28822790e-06 ... 5.63972371e-07
-5.21831787e-07 -9.94766115e-07]
[ 7.45167295e-07 3.55688679e-07 1.15773946e-07 ... 7.99763618e-06
7.19334948e-06 6.26835613e-06]
[ 3.48602309e-07 1.87500662e-06 3.19319823e-06 ... 3.31106000e-06
2.70358563e-06 1.94277926e-06]
...
[ 5.17067054e-06 4.05747927e-06 2.93335543e-06 ... -5.54946242e-06
-5.50878638e-06 -5.26299066e-06]
[ 7.38617217e-06 6.12807183e-06 4.86596465e-06 ... -8.42704701e-06
-8.12953102e-06 -7.67334640e-06]
[ 7.56366149e-06 5.83487060e-06 4.07970764e-06 ... -3.52390454e-06
-3.45058487e-06 -3.19576949e-06]]
[[ 1.67427915e-06 -1.13946695e-06 -3.62678453e-06 ... 4.85706439e-07
4.55079880e-07 9.52289357e-07]
[-5.83282436e-06 -6.13049379e-06 -5.90408157e-06 ... -4.66571775e-07
-6.17774107e-08 5.13695493e-08]
[-1.06519330e-06 -9.20978931e-07 -9.80404889e-07 ... 3.56359963e-06
3.51655502e-06 3.04688327e-06]
...
[-1.48378732e-06 -1.32193529e-06 -1.18729764e-06 ... 4.53864671e-06
3.83354904e-06 3.31875283e-06]
[-3.76960095e-06 -3.78089683e-06 -3.84300244e-06 ... 1.03272991e-05
1.00680286e-05 9.99091390e-06]
[-3.12580784e-06 -3.26408254e-06 -3.44502031e-06 ... 8.85148157e-06
8.56356462e-06 8.50910574e-06]]
...
[[-1.87237854e-06 7.18146951e-07 3.51660927e-06 ... -6.29168059e-06
-4.54383481e-06 -2.11190230e-06]
[ 4.81603907e-06 5.04946591e-06 5.13868853e-06 ... -4.94531185e-06
-4.97220961e-06 -5.07371964e-06]
[ 5.65301378e-06 5.11656564e-06 4.64714044e-06 ... 1.30510483e-06
1.48293489e-06 1.33107029e-06]
...
[ 2.17570774e-07 7.24294584e-07 1.04130851e-06 ... 4.28638637e-06
3.72271948e-06 3.31784829e-06]
[-1.85931552e-07 7.03611458e-07 1.49298204e-06 ... 4.16153876e-06
3.69673032e-06 3.39122725e-06]
[ 7.81214707e-06 8.90456041e-06 9.58787343e-06 ... 3.95649325e-06
3.55336633e-06 3.29187149e-06]]
[[-4.56775313e-06 -3.34700827e-06 -1.85870347e-06 ... 4.29361468e-06
2.94738042e-06 1.80587888e-06]
[-4.12421691e-06 -2.45423672e-06 -8.01773770e-07 ... 4.29305115e-06
5.20202706e-06 6.08471246e-06]
[ 3.27680218e-06 2.48652766e-06 1.25414300e-06 ... 1.40655487e-06
1.67555253e-07 -8.08913443e-07]
...
[-1.51311651e-06 -2.62835174e-06 -3.57270721e-06 ... -2.01864024e-06
-2.51029450e-06 -3.09512036e-06]
[-3.70268660e-06 -4.61556389e-06 -5.31468319e-06 ... -1.35587008e-06
-1.68548067e-06 -2.13219053e-06]
[-7.21197971e-06 -8.13994446e-06 -8.72953656e-06 ... 3.64902277e-06
2.73889986e-06 1.74774836e-06]]
[[-2.86123094e-06 -3.53559767e-06 -4.35971041e-06 ... 4.80155580e-06
5.81152796e-06 6.56062802e-06]
[-6.71461642e-06 -7.43655085e-06 -7.97031815e-06 ... 2.75508035e-06
2.82709293e-06 2.33934311e-06]
[-7.42875044e-06 -7.68666695e-06 -7.85106038e-06 ... 5.48707012e-06
6.75174390e-06 7.43535738e-06]
...
[ 4.94542204e-06 4.97139574e-06 4.92222094e-06 ... -6.45984166e-06
-6.83550041e-06 -6.97351499e-06]
[ 1.90698871e-06 2.13430977e-06 2.27413534e-06 ... -1.77069376e-06
-2.41846962e-06 -2.86636557e-06]
[ 2.26846110e-06 2.35898308e-06 2.37712169e-06 ... -4.31921181e-06
-4.72863701e-06 -4.81716241e-06]]]
(320, 59, 601)
return data for all channels and all time-points for the first 2 epochs
epochs.get_data()[:1] # first 2 epochs
array([[[-1.53682615e-07, 1.76059818e-07, 4.55425791e-08, ...,
4.66550977e-06, 6.94681262e-06, 8.74132001e-06],
[-4.28382745e-06, -3.49376566e-06, -2.85756692e-06, ...,
5.60403187e-06, 5.43679679e-06, 5.40910467e-06],
[-4.85437478e-06, -4.64429674e-06, -4.16165507e-06, ...,
2.27513486e-06, 1.89663829e-06, 1.79428859e-06],
...,
[ 3.35085006e-06, 3.47503013e-06, 3.59880996e-06, ...,
-2.00678158e-08, 1.43032391e-07, 1.75713615e-07],
[ 1.31399230e-06, 1.59594277e-06, 1.87315172e-06, ...,
1.97230798e-06, 2.16159788e-06, 2.08545430e-06],
[ 7.25402012e-07, 1.04189705e-06, 1.34003488e-06, ...,
2.82710672e-06, 3.41396440e-06, 3.85433967e-06]]])
# get data only from last channel of first epoch
epochs.get_data()[0][58] # array of shape (n_epochs, n_channels, n_times)
array([ 7.25402012e-07, 1.04189705e-06, 1.34003488e-06, 1.59969878e-06,
1.79864303e-06, 1.91752791e-06, 1.94524463e-06, 1.88383816e-06,
1.75102161e-06, 1.57914142e-06, 1.41131460e-06, 1.29542790e-06,
1.27588378e-06, 1.38466490e-06, 1.63345919e-06, 2.00927004e-06,
2.47429604e-06, 2.96952822e-06, 3.42224362e-06, 3.75663999e-06,
3.90628001e-06, 3.82543721e-06, 3.49761876e-06, 2.94083845e-06,
2.20736239e-06, 1.37707635e-06, 5.46778039e-07, -1.83185063e-07,
-7.24199222e-07, -1.01321881e-06, -1.02270717e-06, -7.65294039e-07,
-2.92293203e-07, 3.13229067e-07, 9.48214875e-07, 1.50464269e-06,
1.88538563e-06, 2.01879662e-06, 1.86948560e-06, 1.44312972e-06,
7.85190425e-07, -2.60623527e-08, -8.91179942e-07, -1.70444344e-06,
-2.36941662e-06, -2.81278663e-06, -2.99450320e-06, -2.91234651e-06,
-2.60123216e-06, -2.12691103e-06, -1.57550316e-06, -1.04030856e-06,
-6.08283410e-07, -3.47841800e-07, -2.99407625e-07, -4.70464206e-07,
-8.35786708e-07, -1.34211408e-06, -1.91622405e-06, -2.47573224e-06,
-2.94070015e-06, -3.24426663e-06, -3.34152163e-06, -3.21520211e-06,
-2.87657250e-06, -2.36267469e-06, -1.73075179e-06, -1.04942069e-06,
-3.88725456e-07, 1.88972740e-07, 6.36910996e-07, 9.29418721e-07,
1.06418514e-06, 1.06098467e-06, 9.57301458e-07, 8.01972574e-07,
6.46991489e-07, 5.38421295e-07, 5.08692333e-07, 5.71833006e-07,
7.21562516e-07, 9.31839598e-07, 1.16078992e-06, 1.35830683e-06,
1.47486254e-06, 1.46963842e-06, 1.31776050e-06, 1.01564079e-06,
5.82616258e-07, 5.84106584e-08, -5.02485526e-07, -1.03857543e-06,
-1.49094986e-06, -1.81309673e-06, -1.97877086e-06, -1.98623001e-06,
-1.85843549e-06, -1.64002212e-06, -1.39056849e-06, -1.17435864e-06,
-1.04932372e-06, -1.05734347e-06, -1.21727940e-06, -1.52075222e-06,
-1.93242909e-06, -2.39532434e-06, -2.83911133e-06, -3.19023218e-06,
-3.38362111e-06, -3.37364330e-06, -3.14156304e-06, -2.69845392e-06,
-2.08404380e-06, -1.36114630e-06, -6.06561927e-07, 9.97694024e-08,
6.85854803e-07, 1.09639548e-06, 1.29903538e-06, 1.28824640e-06,
1.08411605e-06, 7.26515065e-07, 2.67289613e-07, -2.38316052e-07,
-7.40146351e-07, -1.19957957e-06, -1.59333820e-06, -1.91445979e-06,
-2.16981270e-06, -2.37534567e-06, -2.54980439e-06, -2.70822031e-06,
-2.85712626e-06, -2.99210559e-06, -3.09792589e-06, -3.15133466e-06,
-3.12629216e-06, -3.00041084e-06, -2.76047370e-06, -2.40677038e-06,
-1.95555685e-06, -1.43794567e-06, -8.96268286e-07, -3.78438968e-07,
6.96969057e-08, 4.12126765e-07, 6.28435783e-07, 7.16894361e-07,
6.94848119e-07, 5.95504977e-07, 4.62354715e-07, 3.42153596e-07,
2.76187274e-07, 2.92446472e-07, 4.02133737e-07, 5.98920779e-07,
8.60087026e-07, 1.15158822e-06, 1.43582041e-06, 1.67842149e-06,
1.85443108e-06, 1.95271129e-06, 1.97750107e-06, 1.94668140e-06,
1.88705360e-06, 1.82815225e-06, 1.79560104e-06, 1.80560384e-06,
1.86196864e-06, 1.95589336e-06, 2.06868614e-06, 2.17626061e-06,
2.25510722e-06, 2.28923979e-06, 2.27562494e-06, 2.22579567e-06,
2.16451427e-06, 2.12586904e-06, 2.14657589e-06, 2.25785198e-06,
2.47755350e-06, 2.80497999e-06, 3.21864803e-06, 3.67716851e-06,
4.12471356e-06, 4.49983909e-06, 4.74475034e-06, 4.81451566e-06,
4.68549385e-06, 4.36029677e-06, 3.86792997e-06, 3.26050093e-06,
2.60655468e-06, 1.98146890e-06, 1.45715425e-06, 1.09217909e-06,
9.23588974e-07, 9.62091273e-07, 1.19111124e-06, 1.56941584e-06,
2.03632070e-06, 2.51965595e-06, 2.94521729e-06, 3.24613304e-06,
3.37060827e-06, 3.28795474e-06, 2.99275468e-06, 2.50591510e-06,
1.87316685e-06, 1.16126794e-06, 4.51875424e-07, -1.66512384e-07,
-6.08022330e-07, -7.98418848e-07, -6.83724327e-07, -2.37688628e-07,
5.33919264e-07, 1.59252682e-06, 2.86939793e-06, 4.27227546e-06,
5.69600741e-06, 7.03521502e-06, 8.19687057e-06, 9.11199847e-06,
9.74472430e-06, 1.00967152e-05, 1.02068074e-05, 1.01455073e-05,
1.00040496e-05, 9.88068891e-06, 9.86685335e-06, 1.00343263e-05,
1.04255989e-05, 1.10483179e-05, 1.18749106e-05, 1.28482047e-05,
1.38913610e-05, 1.49193858e-05, 1.58505706e-05, 1.66165748e-05,
1.71701757e-05, 1.74887746e-05, 1.75735170e-05, 1.74447359e-05,
1.71358262e-05, 1.66872043e-05, 1.61403342e-05, 1.55341477e-05,
1.49041996e-05, 1.42829844e-05, 1.37011828e-05, 1.31895768e-05,
1.27795111e-05, 1.25016901e-05, 1.23834125e-05, 1.24435005e-05,
1.26866284e-05, 1.30987352e-05, 1.36442452e-05, 1.42666814e-05,
1.48936759e-05, 1.54450879e-05, 1.58434005e-05, 1.60252758e-05,
1.59515556e-05, 1.56136054e-05, 1.50352434e-05, 1.42696798e-05,
1.33912745e-05, 1.24829218e-05, 1.16225428e-05, 1.08707522e-05,
1.02615791e-05, 9.79869313e-06, 9.45751432e-06, 9.19269309e-06,
8.94923043e-06, 8.67500435e-06, 8.33232517e-06, 7.90671837e-06,
7.41034945e-06, 6.87878105e-06, 6.36266915e-06, 5.91623511e-06,
5.58430685e-06, 5.39032214e-06, 5.32871449e-06, 5.36398190e-06,
5.43609786e-06, 5.47112279e-06, 5.39549306e-06, 5.15138987e-06,
4.71031809e-06, 4.08146235e-06, 3.31259969e-06, 2.48383005e-06,
1.69504807e-06, 1.04840771e-06, 6.29019973e-07, 4.88417028e-07,
6.33912565e-07, 1.02525440e-06, 1.57952400e-06, 2.18445716e-06,
2.71770821e-06, 3.06782770e-06, 3.15417683e-06, 2.94264980e-06,
2.45274788e-06, 1.75442915e-06, 9.56360665e-07, 1.87930855e-07,
-4.22126798e-07, -7.67223983e-07, -7.80578142e-07, -4.45690747e-07,
2.02368033e-07, 1.08400723e-06, 2.08974081e-06, 3.10066211e-06,
4.00928477e-06, 4.73627967e-06, 5.24138666e-06, 5.52666820e-06,
5.63129900e-06, 5.61926528e-06, 5.56282869e-06, 5.52493623e-06,
5.54434144e-06, 5.62620496e-06, 5.74065019e-06, 5.83006033e-06,
5.82339910e-06, 5.65381730e-06, 5.27714034e-06, 4.68827338e-06,
3.93097383e-06, 3.09790192e-06, 2.32210739e-06, 1.76038973e-06,
1.56976490e-06, 1.88213491e-06, 2.78140298e-06, 4.28663255e-06,
6.34446281e-06, 8.83219245e-06, 1.15712339e-05, 1.43485408e-05,
1.69435195e-05, 1.91567260e-05, 2.08350262e-05, 2.18893581e-05,
2.23025936e-05, 2.21270596e-05, 2.14733166e-05, 2.04905400e-05,
1.93414536e-05, 1.81770207e-05, 1.71153694e-05, 1.62265808e-05,
1.55261122e-05, 1.49777968e-05, 1.45052345e-05, 1.40091338e-05,
1.33872380e-05, 1.25545185e-05, 1.14603228e-05, 1.00986970e-05,
8.51131928e-06, 6.78252840e-06, 5.02736544e-06, 3.37431054e-06,
1.94569600e-06, 8.39600995e-07, 1.15510365e-07, -2.13985579e-07,
-1.84335256e-07, 1.26264715e-07, 6.08809994e-07, 1.14037236e-06,
1.60202027e-06, 1.89542640e-06, 1.95603041e-06, 1.76108387e-06,
1.33131409e-06, 7.25574058e-07, 2.99305052e-08, -6.56959947e-07,
-1.23963777e-06, -1.64014049e-06, -1.80949460e-06, -1.73404139e-06,
-1.43572012e-06, -9.67158535e-07, -4.02546218e-07, 1.74241203e-07,
6.82267236e-07, 1.05451588e-06, 1.24580810e-06, 1.23705941e-06,
1.03518871e-06, 6.69062427e-07, 1.82813602e-07, -3.72556744e-07,
-9.48074519e-07, -1.50407882e-06, -2.01429757e-06, -2.46784422e-06,
-2.86819392e-06, -3.22949312e-06, -3.57179493e-06, -3.91613891e-06,
-4.28072026e-06, -4.67790894e-06, -5.11198336e-06, -5.57850309e-06,
-6.06553078e-06, -6.55569725e-06, -7.02825829e-06, -7.46062795e-06,
-7.82968022e-06, -8.11347009e-06, -8.29292991e-06, -8.35298486e-06,
-8.28347594e-06, -8.08090803e-06, -7.75005102e-06, -7.30478129e-06,
-6.76832733e-06, -6.17260481e-06, -5.55576886e-06, -4.95845530e-06,
-4.41954097e-06, -3.97187365e-06, -3.63809065e-06, -3.42690210e-06,
-3.33138574e-06, -3.32964019e-06, -3.38782461e-06, -3.46496435e-06,
-3.51816592e-06, -3.50823791e-06, -3.40510305e-06, -3.19210268e-06,
-2.86708688e-06, -2.44065881e-06, -1.93370346e-06, -1.37334312e-06,
-7.87477679e-07, -2.00820835e-07, 3.67343661e-07, 9.04778590e-07,
1.40652022e-06, 1.87327554e-06, 2.30867821e-06, 2.71627406e-06,
3.09770065e-06, 3.45180801e-06, 3.77439707e-06, 4.05962121e-06,
4.30277383e-06, 4.50289312e-06, 4.66521778e-06, 4.80265389e-06,
4.93463246e-06, 5.08441055e-06, 5.27582278e-06, 5.52884856e-06,
5.85492073e-06, 6.25290217e-06, 6.70670992e-06, 7.18542192e-06,
7.64582634e-06, 8.03746094e-06, 8.30899929e-06, 8.41494446e-06,
8.32223406e-06, 8.01565981e-06, 7.50039011e-06, 6.80254123e-06,
5.96760948e-06, 5.05546362e-06, 4.13337554e-06, 3.26898097e-06,
2.52329872e-06, 1.94362335e-06, 1.55851552e-06, 1.37588334e-06,
1.38340041e-06, 1.55066515e-06, 1.83324932e-06, 2.17835098e-06,
2.53135388e-06, 2.84187900e-06, 3.06866582e-06, 3.18355810e-06,
3.17377096e-06, 3.04131579e-06, 2.80107290e-06, 2.47844163e-06,
2.10549234e-06, 1.71669585e-06, 1.34567296e-06, 1.02205184e-06,
7.69466908e-07, 6.04533957e-07, 5.36499999e-07, 5.68216763e-07,
6.97649152e-07, 9.18644418e-07, 1.22128427e-06, 1.59249138e-06,
2.01677120e-06, 2.47606206e-06, 2.94925403e-06, 3.41232491e-06,
3.83940114e-06, 4.20455901e-06, 4.48401364e-06, 4.65889145e-06,
4.71845289e-06, 4.66254602e-06, 4.50215643e-06, 4.25877246e-06,
3.96269287e-06, 3.64977784e-06, 3.35695804e-06, 3.11753069e-06,
2.95687599e-06, 2.88876896e-06, 2.91308410e-06, 3.01595123e-06,
3.17250854e-06, 3.35070978e-06, 3.51588383e-06, 3.63593258e-06,
3.68659656e-06, 3.65532638e-06, 3.54296122e-06, 3.36329488e-06,
3.14077981e-06, 2.90633660e-06, 2.69221798e-06, 2.52716923e-06,
2.43239163e-06, 2.41831962e-06, 2.48333104e-06, 2.61422255e-06,
2.78836685e-06, 2.97751078e-06, 3.15268988e-06, 3.28869115e-06,
3.36716410e-06, 3.37897351e-06, 3.32587504e-06, 3.21927575e-06,
3.07692411e-06, 2.91883513e-06, 2.76316872e-06, 2.62226515e-06,
2.49976358e-06, 2.38943912e-06, 2.27619633e-06, 2.13848051e-06,
1.95203915e-06, 1.69556317e-06, 1.35673843e-06, 9.36639187e-07,
4.52604540e-07, -6.16397491e-08, -5.58624222e-07, -9.82730042e-07,
-1.27786092e-06, -1.39575792e-06, -1.30477961e-06, -9.96284576e-07,
-4.87778903e-07, 1.76232214e-07, 9.27857189e-07, 1.68389964e-06,
2.35616237e-06, 2.86336912e-06, 3.14261216e-06, 3.15853098e-06,
2.90894889e-06, 2.42592165e-06, 1.77199194e-06, 1.03205586e-06,
3.01831610e-07, -3.24850366e-07, -7.68477626e-07, -9.74142050e-07,
-9.17567287e-07, -6.07215832e-07, -8.15778237e-08, 5.98360091e-07,
1.35905670e-06, 2.12470925e-06, 2.82710672e-06, 3.41396440e-06,
3.85433967e-06])
So to get get the signal amplitude for the last time_point only from the last channel of the first epoch, we would do the following
epochs.get_data()[0][58][600] # array of shape (n_epochs, n_channels, n_times)
3.85433967048037e-06
At this point it honestly get’s quite confusing, so it might be preferable to switch to a pandas DataFrame, although this may cost computation time later on if you’re going to iterate over data for group level analysis etc.
df = epochs.to_data_frame() # create dataframe with nested index
df
| time | condition | epoch | EEG 001 | EEG 002 | EEG 003 | EEG 004 | EEG 005 | EEG 006 | EEG 007 | ... | EEG 050 | EEG 051 | EEG 052 | EEG 054 | EEG 055 | EEG 056 | EEG 057 | EEG 058 | EEG 059 | EEG 060 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | -300 | auditory/right | 0 | -0.153683 | -4.283827 | -4.854375 | -0.359896 | 0.394279 | -4.400797 | -1.202811 | ... | 1.431784 | 2.940984 | 1.983121 | 3.429693 | 3.401887 | 2.569775 | 2.850704 | 3.350850 | 1.313992 | 0.725402 |
| 1 | -298 | auditory/right | 0 | 0.176060 | -3.493766 | -4.644297 | 0.552180 | 1.194767 | -4.472432 | -1.341450 | ... | 1.512172 | 3.084569 | 2.321209 | 3.474450 | 3.641959 | 2.769474 | 2.967791 | 3.475030 | 1.595943 | 1.041897 |
| 2 | -296 | auditory/right | 0 | 0.045543 | -2.857567 | -4.161655 | 1.254199 | 2.031740 | -4.396951 | -1.585917 | ... | 1.583144 | 3.254512 | 2.717577 | 3.489031 | 3.913700 | 3.017219 | 3.061254 | 3.598810 | 1.873152 | 1.340035 |
| 3 | -295 | auditory/right | 0 | -0.487266 | -2.430577 | -3.500332 | 1.659076 | 2.812987 | -4.197414 | -1.938551 | ... | 1.629139 | 3.434417 | 3.133356 | 3.460027 | 4.174354 | 3.271970 | 3.116720 | 3.708310 | 2.110935 | 1.599699 |
| 4 | -293 | auditory/right | 0 | -1.306986 | -2.231490 | -2.770353 | 1.707647 | 3.458586 | -3.905500 | -2.383247 | ... | 1.637843 | 3.602114 | 3.523734 | 3.372418 | 4.380678 | 3.488600 | 3.119026 | 3.786206 | 2.278554 | 1.798643 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 192315 | 693 | buttonpress | 319 | 2.177424 | 1.226092 | 1.980371 | 4.027102 | 3.636770 | 5.895603 | -2.627936 | ... | 0.908393 | 0.714505 | -0.155360 | -4.270140 | -2.087490 | -0.133901 | -5.459906 | -5.161124 | -0.079998 | -2.859459 |
| 192316 | 694 | buttonpress | 319 | 3.568347 | 2.174715 | 3.814056 | 5.023037 | 4.723616 | 7.064501 | -0.862772 | ... | 0.302466 | 0.040847 | -1.079467 | -5.185661 | -2.753452 | -0.917123 | -6.363676 | -5.877935 | -0.965209 | -3.658738 |
| 192317 | 696 | buttonpress | 319 | 4.801556 | 2.755080 | 5.487070 | 6.010036 | 5.894544 | 8.044493 | 1.102437 | ... | -0.300690 | -0.659023 | -2.043852 | -5.954887 | -3.406557 | -1.700440 | -7.101583 | -6.459842 | -1.770694 | -4.319212 |
| 192318 | 698 | buttonpress | 319 | 5.811528 | 2.827093 | 6.751744 | 6.947730 | 7.003489 | 8.759697 | 3.042707 | ... | -0.827598 | -1.294786 | -2.913984 | -6.503422 | -3.974303 | -2.391284 | -7.588334 | -6.835500 | -2.418470 | -4.728637 |
| 192319 | 699 | buttonpress | 319 | 6.560628 | 2.339343 | 7.435357 | 7.795346 | 7.910856 | 9.166593 | 4.723978 | ... | -1.217629 | -1.791663 | -3.578393 | -6.796471 | -4.408558 | -2.925173 | -7.784173 | -6.973515 | -2.866366 | -4.817162 |
192320 rows × 62 columns
df['EEG 001']
0 -0.153683
1 0.176060
2 0.045543
3 -0.487266
4 -1.306986
...
192315 2.177424
192316 3.568347
192317 4.801556
192318 5.811528
192319 6.560628
Name: EEG 001, Length: 192320, dtype: float64
access DataFrame for the first 3 epochs
df.loc[df['epoch'] == 2]
| time | condition | epoch | EEG 001 | EEG 002 | EEG 003 | EEG 004 | EEG 005 | EEG 006 | EEG 007 | ... | EEG 050 | EEG 051 | EEG 052 | EEG 054 | EEG 055 | EEG 056 | EEG 057 | EEG 058 | EEG 059 | EEG 060 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1202 | -300 | auditory/left | 2 | 1.674279 | -5.832824 | -1.065193 | 1.883506 | 5.954980 | 2.699902 | -2.285878 | ... | -0.104895 | -1.505234 | -0.529909 | 1.899286 | -3.035422 | -2.038059 | 1.035239 | -1.483787 | -3.769601 | -3.125808 |
| 1203 | -298 | auditory/left | 2 | -1.139467 | -6.130494 | -0.920979 | 1.742139 | 6.821386 | 1.957775 | -1.995849 | ... | -0.224304 | -1.505949 | -0.838635 | 2.545271 | -2.980840 | -2.069036 | 1.434824 | -1.321935 | -3.780897 | -3.264083 |
| 1204 | -296 | auditory/left | 2 | -3.626785 | -5.904082 | -0.980405 | 1.820046 | 7.347637 | 1.134160 | -1.841423 | ... | -0.337660 | -1.557832 | -1.188400 | 3.153409 | -3.003274 | -2.200103 | 1.786290 | -1.187298 | -3.843002 | -3.445020 |
| 1205 | -295 | auditory/left | 2 | -5.608351 | -5.208556 | -1.205763 | 2.047516 | 7.496192 | 0.325561 | -1.847855 | ... | -0.395011 | -1.616724 | -1.508391 | 3.711745 | -3.050096 | -2.358457 | 2.106030 | -1.042580 | -3.901562 | -3.629170 |
| 1206 | -293 | auditory/left | 2 | -6.982464 | -4.166364 | -1.525351 | 2.319378 | 7.273102 | -0.392720 | -2.024001 | ... | -0.351401 | -1.628021 | -1.722664 | 4.218457 | -3.057204 | -2.458569 | 2.419665 | -0.845292 | -3.896153 | -3.770549 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 1798 | 693 | auditory/left | 2 | 2.043974 | -1.729950 | 2.528953 | -2.284008 | 0.338302 | -12.519796 | -8.186935 | ... | 7.011435 | 2.393073 | 1.964756 | 6.236749 | 7.292279 | 6.802502 | 7.313462 | 6.041348 | 11.048047 | 9.728544 |
| 1799 | 694 | auditory/left | 2 | 1.041975 | -1.069995 | 3.209934 | -2.245922 | 1.779407 | -12.104938 | -8.419878 | ... | 6.809046 | 2.163413 | 1.783681 | 5.497183 | 6.954686 | 6.565084 | 6.652048 | 5.317792 | 10.685427 | 9.278551 |
| 1800 | 696 | auditory/left | 2 | 0.485706 | -0.466572 | 3.563600 | -2.100884 | 3.173691 | -11.122786 | -8.233974 | ... | 6.593292 | 2.003936 | 1.744278 | 4.588079 | 6.616948 | 6.399289 | 5.856608 | 4.538647 | 10.327299 | 8.851482 |
| 1801 | 698 | auditory/left | 2 | 0.455080 | -0.061777 | 3.516555 | -1.933487 | 4.267798 | -9.708467 | -7.613939 | ... | 6.450861 | 1.997810 | 1.904081 | 3.625994 | 6.383641 | 6.379514 | 5.046047 | 3.833549 | 10.068029 | 8.563565 |
| 1802 | 699 | auditory/left | 2 | 0.952289 | 0.051370 | 3.046883 | -1.844444 | 4.837383 | -8.071486 | -6.613888 | ... | 6.458237 | 2.208595 | 2.299780 | 2.735686 | 6.345867 | 6.563920 | 4.340881 | 3.318753 | 9.990914 | 8.509106 |
601 rows × 62 columns
access epochs containing certain conditions
df.loc[df['condition'] == 'auditory/right'] # access epochs containing certain condition
| time | condition | epoch | EEG 001 | EEG 002 | EEG 003 | EEG 004 | EEG 005 | EEG 006 | EEG 007 | ... | EEG 050 | EEG 051 | EEG 052 | EEG 054 | EEG 055 | EEG 056 | EEG 057 | EEG 058 | EEG 059 | EEG 060 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | -300 | auditory/right | 0 | -0.153683 | -4.283827 | -4.854375 | -0.359896 | 0.394279 | -4.400797 | -1.202811 | ... | 1.431784 | 2.940984 | 1.983121 | 3.429693 | 3.401887 | 2.569775 | 2.850704 | 3.350850 | 1.313992 | 0.725402 |
| 1 | -298 | auditory/right | 0 | 0.176060 | -3.493766 | -4.644297 | 0.552180 | 1.194767 | -4.472432 | -1.341450 | ... | 1.512172 | 3.084569 | 2.321209 | 3.474450 | 3.641959 | 2.769474 | 2.967791 | 3.475030 | 1.595943 | 1.041897 |
| 2 | -296 | auditory/right | 0 | 0.045543 | -2.857567 | -4.161655 | 1.254199 | 2.031740 | -4.396951 | -1.585917 | ... | 1.583144 | 3.254512 | 2.717577 | 3.489031 | 3.913700 | 3.017219 | 3.061254 | 3.598810 | 1.873152 | 1.340035 |
| 3 | -295 | auditory/right | 0 | -0.487266 | -2.430577 | -3.500332 | 1.659076 | 2.812987 | -4.197414 | -1.938551 | ... | 1.629139 | 3.434417 | 3.133356 | 3.460027 | 4.174354 | 3.271970 | 3.116720 | 3.708310 | 2.110935 | 1.599699 |
| 4 | -293 | auditory/right | 0 | -1.306986 | -2.231490 | -2.770353 | 1.707647 | 3.458586 | -3.905500 | -2.383247 | ... | 1.637843 | 3.602114 | 3.523734 | 3.372418 | 4.380678 | 3.488600 | 3.119026 | 3.786206 | 2.278554 | 1.798643 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 189911 | 693 | auditory/right | 315 | -5.079067 | -1.246712 | 1.783957 | -8.151322 | -3.918948 | -7.072288 | -5.418097 | ... | 1.261009 | 0.157957 | -3.381464 | -0.743014 | 0.518337 | -1.923513 | -2.839258 | -6.641621 | -2.358054 | -4.796171 |
| 189912 | 694 | auditory/right | 315 | -3.837659 | -2.927242 | 1.225115 | -9.141204 | -4.650545 | -7.129471 | -5.996793 | ... | 1.455271 | 0.235975 | -3.178535 | -0.681336 | 0.589503 | -1.697325 | -2.546469 | -6.249273 | -2.154781 | -3.983449 |
| 189913 | 696 | auditory/right | 315 | -2.791697 | -4.747554 | 0.463874 | -9.929189 | -4.818245 | -6.417768 | -6.079887 | ... | 1.703780 | 0.372526 | -2.914523 | -0.548596 | 0.705804 | -1.404995 | -2.165034 | -5.768835 | -1.912190 | -3.176036 |
| 189914 | 698 | auditory/right | 315 | -2.036109 | -6.489735 | -0.503002 | -10.361328 | -4.388295 | -4.839074 | -5.676215 | ... | 1.956369 | 0.533225 | -2.617024 | -0.355357 | 0.826090 | -1.086330 | -1.738569 | -5.249411 | -1.660041 | -2.441243 |
| 189915 | 699 | auditory/right | 315 | -1.617244 | -7.930955 | -1.657449 | -10.331967 | -3.431832 | -2.451649 | -4.878071 | ... | 2.166444 | 0.684737 | -2.309054 | -0.106292 | 0.914984 | -0.774094 | -1.304022 | -4.733976 | -1.419392 | -1.822676 |
43873 rows × 62 columns
looking at the first epoch for auditory stimuli presented on the right
df.loc[(df['condition'] == 'auditory/right') & (df['epoch'] == 0)]
| time | condition | epoch | EEG 001 | EEG 002 | EEG 003 | EEG 004 | EEG 005 | EEG 006 | EEG 007 | ... | EEG 050 | EEG 051 | EEG 052 | EEG 054 | EEG 055 | EEG 056 | EEG 057 | EEG 058 | EEG 059 | EEG 060 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | -300 | auditory/right | 0 | -0.153683 | -4.283827 | -4.854375 | -0.359896 | 0.394279 | -4.400797 | -1.202811 | ... | 1.431784 | 2.940984 | 1.983121 | 3.429693 | 3.401887 | 2.569775 | 2.850704 | 3.350850 | 1.313992 | 0.725402 |
| 1 | -298 | auditory/right | 0 | 0.176060 | -3.493766 | -4.644297 | 0.552180 | 1.194767 | -4.472432 | -1.341450 | ... | 1.512172 | 3.084569 | 2.321209 | 3.474450 | 3.641959 | 2.769474 | 2.967791 | 3.475030 | 1.595943 | 1.041897 |
| 2 | -296 | auditory/right | 0 | 0.045543 | -2.857567 | -4.161655 | 1.254199 | 2.031740 | -4.396951 | -1.585917 | ... | 1.583144 | 3.254512 | 2.717577 | 3.489031 | 3.913700 | 3.017219 | 3.061254 | 3.598810 | 1.873152 | 1.340035 |
| 3 | -295 | auditory/right | 0 | -0.487266 | -2.430577 | -3.500332 | 1.659076 | 2.812987 | -4.197414 | -1.938551 | ... | 1.629139 | 3.434417 | 3.133356 | 3.460027 | 4.174354 | 3.271970 | 3.116720 | 3.708310 | 2.110935 | 1.599699 |
| 4 | -293 | auditory/right | 0 | -1.306986 | -2.231490 | -2.770353 | 1.707647 | 3.458586 | -3.905500 | -2.383247 | ... | 1.637843 | 3.602114 | 3.523734 | 3.372418 | 4.380678 | 3.488600 | 3.119026 | 3.786206 | 2.278554 | 1.798643 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 596 | 693 | auditory/right | 0 | -0.455145 | 6.226211 | 3.524521 | -1.760868 | 1.436730 | -0.952867 | -0.575605 | ... | -5.390209 | 7.107356 | 6.180171 | -2.608987 | 6.799990 | 9.376177 | -3.391412 | -0.670084 | 0.983064 | 1.359057 |
| 597 | 694 | auditory/right | 0 | 2.112229 | 5.886371 | 2.854166 | -1.546046 | 0.293328 | -0.279262 | -1.076823 | ... | -5.279555 | 7.422220 | 6.893315 | -2.349400 | 6.982848 | 10.153623 | -3.134838 | -0.302329 | 1.557232 | 2.124709 |
| 598 | 696 | auditory/right | 0 | 4.665510 | 5.604032 | 2.275135 | -1.128092 | -0.678382 | 0.720977 | -1.028660 | ... | -5.317972 | 7.551767 | 7.389360 | -2.155697 | 6.942251 | 10.714484 | -2.914002 | -0.020068 | 1.972308 | 2.827107 |
| 599 | 698 | auditory/right | 0 | 6.946813 | 5.436797 | 1.896638 | -0.548043 | -1.324796 | 1.912227 | -0.405261 | ... | -5.549491 | 7.445577 | 7.609505 | -2.030483 | 6.642568 | 10.979282 | -2.739930 | 0.143032 | 2.161598 | 3.413964 |
| 600 | 699 | auditory/right | 0 | 8.741320 | 5.409105 | 1.794289 | 0.125558 | -1.529215 | 3.150932 | 0.748562 | ... | -5.992314 | 7.084145 | 7.532212 | -1.962733 | 6.079477 | 10.904114 | -2.610461 | 0.175714 | 2.085454 | 3.854340 |
601 rows × 62 columns
looking at the signal from a single electrode for the first epoch for auditory stimuli presented on the right (jeez)
# looking at a subset of the dataframe
df.loc[(df['condition'] == 'auditory/right') & (df['epoch'] == 0)]['EEG 001']
0 -0.153683
1 0.176060
2 0.045543
3 -0.487266
4 -1.306986
...
596 -0.455145
597 2.112229
598 4.665510
599 6.946813
600 8.741320
Name: EEG 001, Length: 601, dtype: float64
4.2 rejecting bad epochs¶
As discussed earlier we’ll get rid of epochs containing artifacts.
This way we’ll only reject a small subset of relevant data, while the rejection of ICA components or whole channels might have lead to a greater loss of relevant data in the signal. This is one of the reasons why we collect so many trials in EEG experiments.
As a point of caution, epoch rejection is best done after repairing our signal for eye-blinks, as otherwise we might lose a significant number of epochs.
for more information see the MNE tutorial: Rejecting Epochs based on channel amplitude
For now we’ll simply reject eppochs by maximum(minimum peak-to-peak signal value thresholds (exceeding 100 µV, as it’s highly unlikely that any eeg-signal may reach this amplitude or epochs with channel with signal below 1 µV to get rid of flat channels) using the epochs.drop_bad() function.
# define upper and lower threshold as dict(channel_type:criteria)
reject_criteria_upper = dict(eeg=100e-6) # 100 µV
reject_criteria_flat = dict(eeg=1e-6) # 1 µV
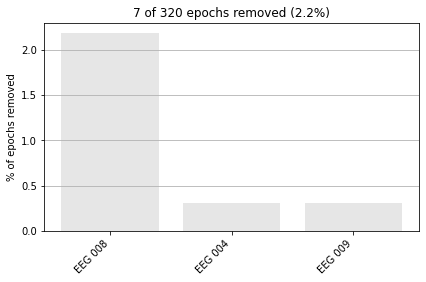
epochs.drop_bad(reject=reject_criteria_upper, flat=reject_criteria_flat)
Rejecting epoch based on EEG : ['EEG 008', 'EEG 009']
Rejecting epoch based on EEG : ['EEG 008']
Rejecting epoch based on EEG : ['EEG 004', 'EEG 008']
Rejecting epoch based on EEG : ['EEG 008']
Rejecting epoch based on EEG : ['EEG 008']
Rejecting epoch based on EEG : ['EEG 008']
Rejecting epoch based on EEG : ['EEG 008']
7 bad epochs dropped
| Number of events | 313 |
|---|---|
| Events | auditory/left: 70 auditory/right: 72 buttonpress: 16 face: 14 visual/left: 71 visual/right: 70 |
| Time range | -0.300 – 0.699 sec |
| Baseline | -0.300 – 0.000 sec |
We can then further visulaize how many epochs were dropped for each channel.
epochs.plot_drop_log();
If no arguments are provided for the drop_bad() function, all epochs that were marked as bad would be dropped.
Another strategy for rejecting epochs is to declare the above criteria while creating the epochs object
We can specify where in the epoch to look for artifacts with the reject_tmin and reject_tmax parameters of mne.Epochs(). Reject_tmin = 0 would mean that we look for artifacts after the event, while reject_tmax = 0 would mean that we only look for artifacts in the timeframe before the event occurde. If not specified they default to the ends of the timeframe specified for the epochs.
epochs = mne.Epochs(reconst_sig,
events,
picks=['eeg'],
tmin=-0.3, tmax=0.7,
reject_tmin=-0.3,
reject_tmax=0,
reject=reject_criteria_upper,
flat=reject_criteria_flat,
preload=True)
Not setting metadata
320 matching events found
Setting baseline interval to [-0.2996928197375818, 0.0] sec
Applying baseline correction (mode: mean)
0 projection items activated
Using data from preloaded Raw for 320 events and 601 original time points ...
Rejecting epoch based on EEG : ['EEG 008']
1 bad epochs dropped
For the automatic rejection of epochs we can use the reject_by_annotation parameter. This can be achieved by adding information about the timeframe of an artifact, break, experimental block etc. to an mne.Annotations object and using the .set_annotations() function to add this to the .info object of our data.
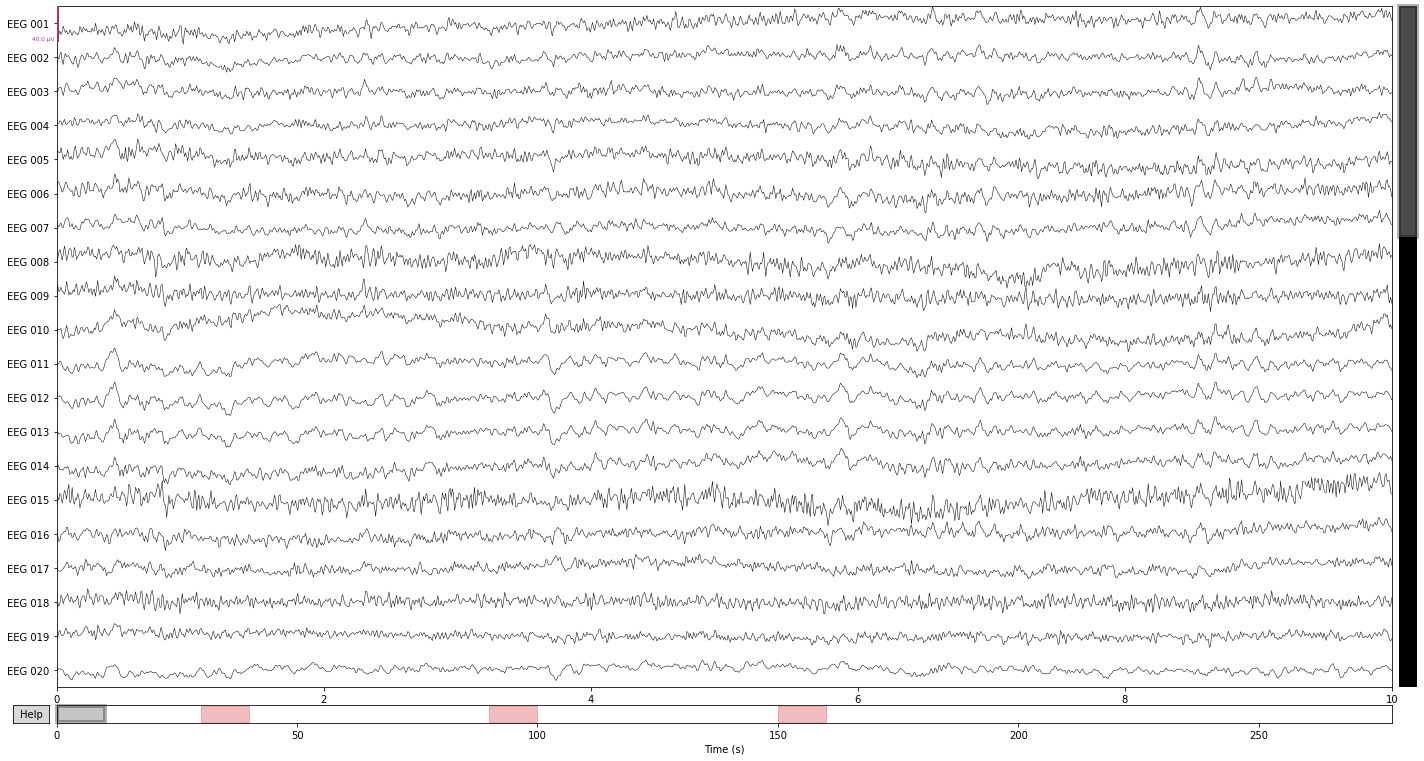
So we’ll define 3 hypothetical breaks in the next step by specfifying their onset time, duration and adding a description. If the description contains the string “bad” annotated data-spans will be automatically excluded from most analysis steps, including the creation of epochs.
onset_breaks = [reconst_sig.first_time + 30, reconst_sig.first_time + 90, reconst_sig.first_time + 150]
durations = [10, 10, 10]
description_breaks = ['bad_break_1', 'bad_break_2', 'bad_break_3']
Now we create our Annotations object
breaks = mne.Annotations(onset=onset_breaks,
duration=durations,
description=description_breaks,
orig_time=raw.info['meas_date'])
and set the annotations to our raw object.
reconst_sig.set_annotations(reconst_sig.annotations + breaks)
| Measurement date | December 03, 2002 19:01:10 GMT |
|---|---|
| Experimenter | MEG | Participant | Unknown |
| Digitized points | 0 points |
| Good channels | 59 EEG |
| Bad channels | None |
| EOG channels | Not available |
| ECG channels | Not available |
| Sampling frequency | 600.61 Hz |
| Highpass | 0.10 Hz |
| Lowpass | 40.00 Hz |
| Filenames | sample_audvis_raw.fif |
| Duration | 00:04:37 (HH:MM:SS) |
Let's check how this look in our interactive plots
reconst_sig.plot();
Opening raw-browser...
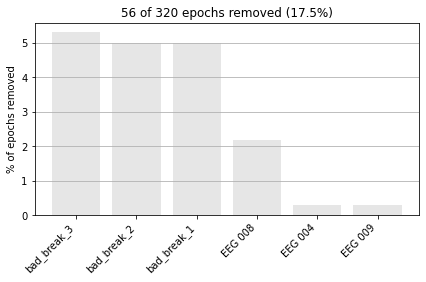
Now when we create our epochs object, any epoch contained in the designated “breaks” will be excluded.
epochs = mne.Epochs(reconst_sig,
events,
picks=['eeg'],
tmin=-0.3, tmax=0.7,
#reject_tmin=-0.3,
#reject_tmax=0,
reject=reject_criteria_upper,
flat=reject_criteria_flat,
reject_by_annotation=True,
preload=True)
epochs.event_id = event_dict # rename our events
Not setting metadata
320 matching events found
Setting baseline interval to [-0.2996928197375818, 0.0] sec
Applying baseline correction (mode: mean)
0 projection items activated
Using data from preloaded Raw for 320 events and 601 original time points ...
Rejecting epoch based on EEG : ['EEG 008', 'EEG 009']
Rejecting epoch based on EEG : ['EEG 008']
Rejecting epoch based on EEG : ['EEG 004', 'EEG 008']
Rejecting epoch based on EEG : ['EEG 008']
Rejecting epoch based on EEG : ['EEG 008']
Rejecting epoch based on EEG : ['EEG 008']
Rejecting epoch based on EEG : ['EEG 008']
56 bad epochs dropped
epochs.event_id
{'auditory/left': 1,
'auditory/right': 2,
'visual/left': 3,
'visual/right': 4,
'face': 5,
'buttonpress': 32}
and to visualize the dropped epochs.
epochs.plot_drop_log();
Now we could convert this data into a dataframe for further maipulation or export our epochs as an tsv file in long format for statistical analysis.
df = epochs.to_data_frame(index=['condition', 'epoch', 'time']) # create dataframe with nested index
df.sort_index(inplace=True)
df
| channel | EEG 001 | EEG 002 | EEG 003 | EEG 004 | EEG 005 | EEG 006 | EEG 007 | EEG 008 | EEG 009 | EEG 010 | ... | EEG 050 | EEG 051 | EEG 052 | EEG 054 | EEG 055 | EEG 056 | EEG 057 | EEG 058 | EEG 059 | EEG 060 | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| condition | epoch | time | |||||||||||||||||||||
| auditory/left | 2 | -300 | 1.674279 | -5.832824 | -1.065193 | 1.883506 | 5.954980 | 2.699902 | -2.285878 | -1.041173 | 1.371179 | 2.461690 | ... | -0.104895 | -1.505234 | -0.529909 | 1.899286 | -3.035422 | -2.038059 | 1.035239 | -1.483787 | -3.769601 | -3.125808 |
| -298 | -1.139467 | -6.130494 | -0.920979 | 1.742139 | 6.821386 | 1.957775 | -1.995849 | 0.406024 | 0.980153 | 2.041891 | ... | -0.224304 | -1.505949 | -0.838635 | 2.545271 | -2.980840 | -2.069036 | 1.434824 | -1.321935 | -3.780897 | -3.264083 | ||
| -296 | -3.626785 | -5.904082 | -0.980405 | 1.820046 | 7.347637 | 1.134160 | -1.841423 | 2.170672 | 0.731463 | 1.703899 | ... | -0.337660 | -1.557832 | -1.188400 | 3.153409 | -3.003274 | -2.200103 | 1.786290 | -1.187298 | -3.843002 | -3.445020 | ||
| -295 | -5.608351 | -5.208556 | -1.205763 | 2.047516 | 7.496192 | 0.325561 | -1.847855 | 3.967159 | 0.648780 | 1.442463 | ... | -0.395011 | -1.616724 | -1.508391 | 3.711745 | -3.050096 | -2.358457 | 2.106030 | -1.042580 | -3.901562 | -3.629170 | ||
| -293 | -6.982464 | -4.166364 | -1.525351 | 2.319378 | 7.273102 | -0.392720 | -2.024001 | 5.483102 | 0.738784 | 1.243973 | ... | -0.351401 | -1.628021 | -1.722664 | 4.218457 | -3.057204 | -2.458569 | 2.419665 | -0.845292 | -3.896153 | -3.770549 | ||
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| visual/right | 318 | 693 | 7.132074 | 2.962601 | 4.083015 | 6.192311 | 4.220870 | 2.193333 | -2.139301 | 4.822322 | 7.136358 | 2.772771 | ... | -3.877052 | -3.739459 | -1.819167 | -3.514831 | -3.185711 | -3.474153 | -1.837076 | -1.615154 | -1.390848 | 4.738347 |
| 694 | 5.733377 | 3.510989 | 2.754277 | 7.373238 | 4.454477 | 2.821823 | -2.153671 | 8.907488 | 5.166448 | 2.031963 | ... | -3.833959 | -3.616641 | -1.841351 | -3.399617 | -3.245535 | -3.390298 | -1.811255 | -1.702233 | -1.236660 | 4.347359 | ||
| 696 | 4.293615 | 4.293051 | 1.406555 | 8.565687 | 4.861299 | 3.564821 | -1.755798 | 13.013912 | 3.079259 | 1.418302 | ... | -3.879939 | -3.601303 | -1.966689 | -3.508406 | -3.450976 | -3.458747 | -2.040714 | -2.018640 | -1.355870 | 3.649023 | ||
| 698 | 2.947380 | 5.202027 | 0.167555 | 9.551748 | 5.305607 | 4.120528 | -1.106711 | 16.533834 | 1.150853 | 0.947768 | ... | -3.953208 | -3.625353 | -2.126498 | -3.826098 | -3.719349 | -3.617442 | -2.494923 | -2.510294 | -1.685481 | 2.738900 | ||
| 699 | 1.805879 | 6.084712 | -0.808913 | 10.152494 | 5.633928 | 4.214714 | -0.385346 | 18.988465 | -0.379245 | 0.601400 | ... | -3.987063 | -3.616629 | -2.246846 | -4.308630 | -3.959156 | -3.792737 | -3.110733 | -3.095120 | -2.132191 | 1.747748 |
158664 rows × 59 columns
df.to_csv(output_path + str(os.sep) + 'sub-test_ses-001_sample_audiovis_eeg_data_epo.tsv',
sep='\t')
epochs.event_id
{'auditory/left': 1,
'auditory/right': 2,
'visual/left': 3,
'visual/right': 4,
'face': 5,
'buttonpress': 32}
Or save the epochs as a .fif file using epochs.save() which can be imported back into mne using the .read_epochs() function.
epochs.save(output_path + str(os.sep) + 'sub-test_ses-001_sample_audiovis_eeg_data_epo.fif',
overwrite=True)