# Let's keep our notebook clean, so it's a little more readable!
import warnings
warnings.filterwarnings('ignore')
%matplotlib inline
Machine learning to predict age from rs-fmri¶
The goal is to extract data from several rs-fmri images, and use that data as features in a machine learning model. We will integrate what we’ve learned in the previous machine learning lecture to build an unbiased model and test it on a left out sample.
We’re going to use a dataset that was prepared for this tutorial by Elizabeth Dupre, Jake Vogel and Gael Varoquaux, by preprocessing ds000228 (from Richardson et al. (2018)) through fmriprep. They also created this tutorial and should be credited for it.
Load the data¶
# change this to the location where you downloaded the data
wdir = '/data/ds000228/'
# Now fetch the data
from glob import glob
import os
data = sorted(glob(os.path.join(wdir,'*.gz')))
confounds = sorted(glob(os.path.join(wdir,'*regressors.tsv')))
How many individual subjects do we have?
#len(data.func)
len(data)
155
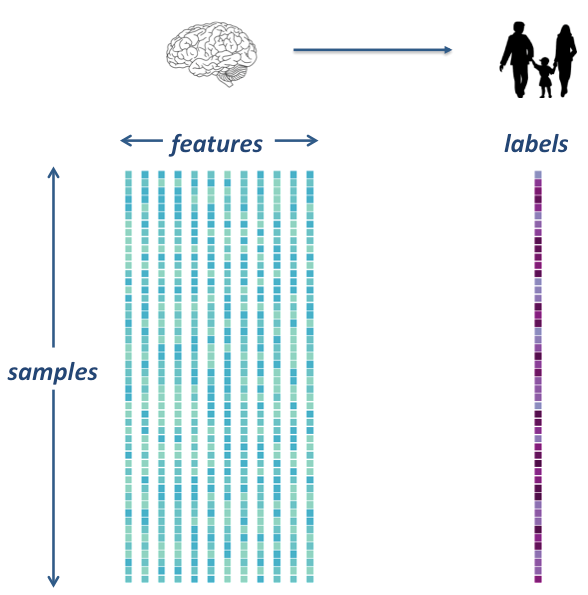
Extract features¶

In order to do our machine learning, we will need to extract feature from our rs-fmri images.
Specifically, we will extract signals from a brain parcellation and compute a correlation matrix, representing regional coactivation between regions.
We will practice on one subject first, then we’ll extract data for all subjects
Retrieve the atlas for extracting features and an example subject¶
Since we’re using rs-fmri data, it makes sense to use an atlas defined using rs-fmri data
This paper has many excellent insights about what kind of atlas to use for an rs-fmri machine learning task. See in particular Figure 5.
https://www.sciencedirect.com/science/article/pii/S1053811919301594?via=ihub
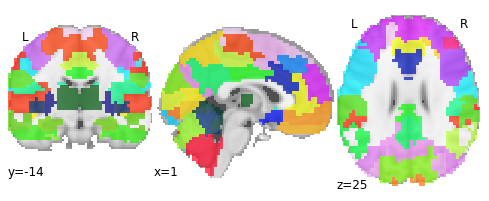
Let’s use the MIST atlas, created here in Montreal using the BASC method. This atlas has multiple resolutions, for larger networks or finer-grained ROIs. Let’s use a 64-ROI atlas to allow some detail, but to ultimately keep our connectivity matrices manageable
Here is a link to the MIST paper: https://mniopenresearch.org/articles/1-3
from nilearn import datasets
parcellations = datasets.fetch_atlas_basc_multiscale_2015(version='sym')
atlas_filename = parcellations.scale064
print('Atlas ROIs are located in nifti image (4D) at: %s' %
atlas_filename)
Dataset created in /home/neuro/nilearn_data/basc_multiscale_2015
Downloading data from https://ndownloader.figshare.com/files/1861819 ...
Atlas ROIs are located in nifti image (4D) at: /home/neuro/nilearn_data/basc_multiscale_2015/template_cambridge_basc_multiscale_nii_sym/template_cambridge_basc_multiscale_sym_scale064.nii.gz
...done. (1 seconds, 0 min)
Extracting data from /home/neuro/nilearn_data/basc_multiscale_2015/3cbcf0eeb3f666f55070aba1db9a758f/1861819..... done.
Let’s have a look at that atlas
from nilearn import plotting
plotting.plot_roi(atlas_filename, draw_cross=False)
<nilearn.plotting.displays.OrthoSlicer at 0x7f5beb186a50>
Great, let’s load an example 4D fmri time-series for one subject
fmri_filenames = data[0]
print(fmri_filenames)
/data/ds000228/sub-pixar001_task-pixar_space-MNI152NLin2009cAsym_desc-preproc_bold.nii.gz
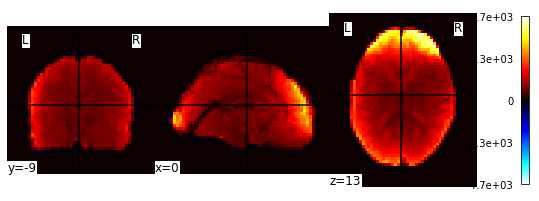
Let’s have a look at the image! Because it is a 4D image, we can only look at one slice at a time. Or, better yet, let’s look at an average image!
from nilearn import image
averaged_Img = image.mean_img(image.mean_img(fmri_filenames))
plotting.plot_stat_map(averaged_Img)
<nilearn.plotting.displays.OrthoSlicer at 0x7f5be87b5b50>
Extract signals on a parcellation defined by labels¶
Using the NiftiLabelsMasker
So we’ve loaded our atlas and 4D data for a single subject. Let’s practice extracting features!
from nilearn.input_data import NiftiLabelsMasker
masker = NiftiLabelsMasker(labels_img=atlas_filename, standardize=True,
memory='nilearn_cache', verbose=1)
# Here we go from nifti files to the signal time series in a numpy
# array. Note how we give confounds to be regressed out during signal
# extraction
conf = confounds[0]
time_series = masker.fit_transform(fmri_filenames, confounds=conf)
[NiftiLabelsMasker.fit_transform] loading data from /home/neuro/nilearn_data/basc_multiscale_2015/template_cambridge_basc_multiscale_nii_sym/template_cambridge_basc_multiscale_sym_scale064.nii.gz
Resampling labels
________________________________________________________________________________
[Memory] Calling nilearn.input_data.base_masker.filter_and_extract...
filter_and_extract('/data/ds000228/sub-pixar001_task-pixar_space-MNI152NLin2009cAsym_desc-preproc_bold.nii.gz',
<nilearn.input_data.nifti_labels_masker._ExtractionFunctor object at 0x7f5be86a1bd0>,
{ 'background_label': 0,
'detrend': False,
'dtype': None,
'high_pass': None,
'labels_img': '/home/neuro/nilearn_data/basc_multiscale_2015/template_cambridge_basc_multiscale_nii_sym/template_cambridge_basc_multiscale_sym_scale064.nii.gz',
'low_pass': None,
'mask_img': None,
'smoothing_fwhm': None,
'standardize': True,
'strategy': 'mean',
't_r': None,
'target_affine': None,
'target_shape': None}, confounds='/data/ds000228/sub-pixar001_task-pixar_desc-confounds_regressors.tsv', dtype=None, memory=Memory(location=nilearn_cache/joblib), memory_level=1, verbose=1)
[NiftiLabelsMasker.transform_single_imgs] Loading data from /data/ds000228/sub-pixar001_task-pixar_space-MNI152NLin2009cAsym_desc-preproc_bold.nii.gz
[NiftiLabelsMasker.transform_single_imgs] Extracting region signals
[NiftiLabelsMasker.transform_single_imgs] Cleaning extracted signals
_______________________________________________filter_and_extract - 1.1s, 0.0min
So what did we just create here?
type(time_series)
numpy.ndarray
time_series.shape
(168, 64)
What are these “confounds” and how are they used?
import pandas
conf_df = pandas.read_table(conf)
conf_df.head()
| csf | white_matter | global_signal | std_dvars | dvars | framewise_displacement | t_comp_cor_00 | t_comp_cor_01 | t_comp_cor_02 | t_comp_cor_03 | ... | cosine00 | cosine01 | cosine02 | cosine03 | trans_x | trans_y | trans_z | rot_x | rot_y | rot_z | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 818.550141 | 875.069943 | 1262.020140 | 0.000000 | 0.000000 | 0.000000 | -0.020679 | -0.033857 | 0.095524 | -0.022131 | ... | 0.109104 | 0.109090 | 0.109066 | 0.109033 | 0.013422 | -0.235811 | 0.033243 | -0.000900 | -9.976860e-24 | 0.000152 |
| 1 | 815.643544 | 873.886244 | 1260.829698 | 1.320145 | 37.240650 | 0.124271 | -0.007043 | -0.045004 | -0.032265 | -0.000439 | ... | 0.109066 | 0.108937 | 0.108723 | 0.108423 | 0.030943 | -0.238651 | 0.088048 | -0.001747 | -1.329770e-04 | 0.000154 |
| 2 | 820.769909 | 872.997093 | 1262.678653 | 1.299640 | 36.662231 | 0.052546 | -0.005027 | -0.089152 | -0.052859 | -0.083313 | ... | 0.108990 | 0.108632 | 0.108038 | 0.107207 | 0.012759 | -0.230284 | 0.097429 | -0.001644 | -0.000000e+00 | 0.000250 |
| 3 | 816.815767 | 872.913170 | 1261.592396 | 1.540568 | 43.458698 | 0.100117 | 0.053507 | -0.081439 | 0.029216 | -0.002027 | ... | 0.108875 | 0.108176 | 0.107012 | 0.105391 | 0.010014 | -0.213517 | 0.143186 | -0.001455 | 9.294130e-05 | 0.000665 |
| 4 | 818.287589 | 872.019839 | 1249.983704 | 2.743071 | 77.380722 | 0.272004 | 0.025015 | -0.061691 | 0.023856 | -0.159531 | ... | 0.108723 | 0.107567 | 0.105651 | 0.102986 | 0.059444 | -0.259451 | 0.083982 | -0.000378 | 3.686370e-04 | 0.001661 |
5 rows × 28 columns
conf_df.shape
(168, 28)
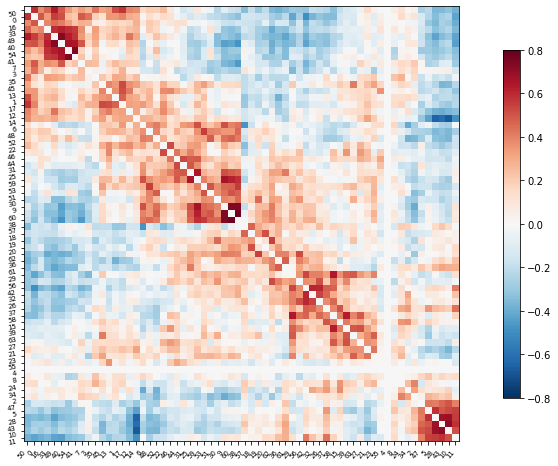
Compute and display a correlation matrix¶
from nilearn.connectome import ConnectivityMeasure
correlation_measure = ConnectivityMeasure(kind='correlation')
correlation_matrix = correlation_measure.fit_transform([time_series])[0]
correlation_matrix.shape
(64, 64)
Plot the correlation matrix
import numpy as np
# Mask the main diagonal for visualization:
np.fill_diagonal(correlation_matrix, 0)
# The labels we have start with the background (0), hence we skip the
# first label
plotting.plot_matrix(correlation_matrix, figure=(10, 8),
labels=range(time_series.shape[-1]),
vmax=0.8, vmin=-0.8, reorder=True)
# matrices are ordered for block-like representation
<matplotlib.image.AxesImage at 0x7f5be82a2b90>
Extract features from the whole dataset¶
Here, we are going to use a for loop to iterate through each image and use the same techniques we learned above to extract rs-fmri connectivity features from every subject.
# Here is a really simple for loop
for i in range(10):
print('the number is', i)
the number is 0
the number is 1
the number is 2
the number is 3
the number is 4
the number is 5
the number is 6
the number is 7
the number is 8
the number is 9
container = []
for i in range(10):
container.append(i)
container
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
Now lets construct a more complicated loop to do what we want
First we do some things we don’t need to do in the loop. Let’s reload our atlas, and re-initiate our masker and correlation_measure
from nilearn.input_data import NiftiLabelsMasker
from nilearn.connectome import ConnectivityMeasure
from nilearn import datasets
# load atlas
multiscale = datasets.fetch_atlas_basc_multiscale_2015()
atlas_filename = multiscale.scale064
# initialize masker (change verbosity)
masker = NiftiLabelsMasker(labels_img=atlas_filename, standardize=True,
memory='nilearn_cache', verbose=0)
# initialize correlation measure, set to vectorize
correlation_measure = ConnectivityMeasure(kind='correlation', vectorize=True,
discard_diagonal=True)
Okay – now that we have that taken care of, let’s run our big loop!
NOTE: On a laptop, this might a few minutes.
all_features = [] # here is where we will put the data (a container)
for i,sub in enumerate(data):
# extract the timeseries from the ROIs in the atlas
time_series = masker.fit_transform(sub, confounds=confounds[i])
# create a region x region correlation matrix
correlation_matrix = correlation_measure.fit_transform([time_series])[0]
# add to our container
all_features.append(correlation_matrix)
# keep track of status
print('finished %s of %s'%(i+1,len(data)))
finished 1 of 155
finished 2 of 155
finished 3 of 155
finished 4 of 155
finished 5 of 155
finished 6 of 155
finished 7 of 155
finished 8 of 155
finished 9 of 155
finished 10 of 155
finished 11 of 155
finished 12 of 155
finished 13 of 155
finished 14 of 155
finished 15 of 155
finished 16 of 155
finished 17 of 155
finished 18 of 155
finished 19 of 155
finished 20 of 155
finished 21 of 155
finished 22 of 155
finished 23 of 155
finished 24 of 155
finished 25 of 155
finished 26 of 155
finished 27 of 155
finished 28 of 155
finished 29 of 155
finished 30 of 155
finished 31 of 155
finished 32 of 155
finished 33 of 155
finished 34 of 155
finished 35 of 155
finished 36 of 155
finished 37 of 155
finished 38 of 155
finished 39 of 155
finished 40 of 155
finished 41 of 155
finished 42 of 155
finished 43 of 155
finished 44 of 155
finished 45 of 155
finished 46 of 155
finished 47 of 155
finished 48 of 155
finished 49 of 155
finished 50 of 155
finished 51 of 155
finished 52 of 155
finished 53 of 155
finished 54 of 155
finished 55 of 155
finished 56 of 155
finished 57 of 155
finished 58 of 155
finished 59 of 155
finished 60 of 155
finished 61 of 155
finished 62 of 155
finished 63 of 155
finished 64 of 155
finished 65 of 155
finished 66 of 155
finished 67 of 155
finished 68 of 155
finished 69 of 155
finished 70 of 155
finished 71 of 155
finished 72 of 155
finished 73 of 155
finished 74 of 155
finished 75 of 155
finished 76 of 155
finished 77 of 155
finished 78 of 155
finished 79 of 155
finished 80 of 155
finished 81 of 155
finished 82 of 155
finished 83 of 155
finished 84 of 155
finished 85 of 155
finished 86 of 155
finished 87 of 155
finished 88 of 155
finished 89 of 155
finished 90 of 155
finished 91 of 155
finished 92 of 155
finished 93 of 155
finished 94 of 155
finished 95 of 155
finished 96 of 155
finished 97 of 155
finished 98 of 155
finished 99 of 155
finished 100 of 155
finished 101 of 155
finished 102 of 155
finished 103 of 155
finished 104 of 155
finished 105 of 155
finished 106 of 155
finished 107 of 155
finished 108 of 155
finished 109 of 155
finished 110 of 155
finished 111 of 155
finished 112 of 155
finished 113 of 155
finished 114 of 155
finished 115 of 155
finished 116 of 155
finished 117 of 155
finished 118 of 155
finished 119 of 155
finished 120 of 155
finished 121 of 155
finished 122 of 155
finished 123 of 155
finished 124 of 155
finished 125 of 155
finished 126 of 155
finished 127 of 155
finished 128 of 155
finished 129 of 155
finished 130 of 155
finished 131 of 155
finished 132 of 155
finished 133 of 155
finished 134 of 155
finished 135 of 155
finished 136 of 155
finished 137 of 155
finished 138 of 155
finished 139 of 155
finished 140 of 155
finished 141 of 155
finished 142 of 155
finished 143 of 155
finished 144 of 155
finished 145 of 155
finished 146 of 155
finished 147 of 155
finished 148 of 155
finished 149 of 155
finished 150 of 155
finished 151 of 155
finished 152 of 155
finished 153 of 155
finished 154 of 155
finished 155 of 155
# Let's save the data to disk
import numpy as np
np.savez_compressed('MAIN_BASC064_subsamp_features',a = all_features)
In case you do not want to run the full loop on your computer, you can load the output of the loop here!
import requests
url = 'https://www.dropbox.com/s/v48f8pjfw4u2bxi/MAIN_BASC064_subsamp_features.npz?dl=1'
myfile = requests.get(url)
open('data/MAIN_BASC064_subsamp_features.npz', 'wb').write(myfile.content)
2384912
feat_file = 'data/MAIN_BASC064_subsamp_features.npz'
X_features = np.load(feat_file, allow_pickle=True)['a']
We just make sure everything looks like expected.
X_features.shape
(155, 2016)
Okay so we’ve got our features.
We can visualize our feature matrix
import matplotlib.pyplot as plt
plt.imshow(X_features, aspect='auto')
plt.colorbar()
plt.title('feature matrix')
plt.xlabel('features')
plt.ylabel('subjects')
Text(0, 0.5, 'subjects')

Get Y (our target) and assess its distribution¶
# Let's load the phenotype data
pheno_path = os.path.join(wdir, 'participants.tsv')
import pandas
pheno = pandas.read_csv(pheno_path, sep='\t').sort_values('participant_id')
pheno.head()
| participant_id | Age | AgeGroup | Child_Adult | Gender | Handedness | ToM Booklet-Matched | ToM Booklet-Matched-NOFB | FB_Composite | FB_Group | WPPSI BD raw | WPPSI BD scaled | KBIT_raw | KBIT_standard | DCCS Summary | Scanlog: Scanner | Scanlog: Coil | Scanlog: Voxel slize | Scanlog: Slice Gap | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | sub-pixar001 | 4.774812 | 4yo | child | M | R | 0.80 | 0.736842 | 6.0 | pass | 22.0 | 13.0 | NaN | NaN | 3.0 | 3T1 | 7-8yo 32ch | 3mm iso | 0.1 |
| 1 | sub-pixar002 | 4.856947 | 4yo | child | F | R | 0.72 | 0.736842 | 4.0 | inc | 18.0 | 9.0 | NaN | NaN | 2.0 | 3T1 | 7-8yo 32ch | 3mm iso | 0.1 |
| 2 | sub-pixar003 | 4.153320 | 4yo | child | F | R | 0.44 | 0.421053 | 3.0 | inc | 15.0 | 9.0 | NaN | NaN | 3.0 | 3T1 | 7-8yo 32ch | 3mm iso | 0.1 |
| 3 | sub-pixar004 | 4.473648 | 4yo | child | F | R | 0.64 | 0.736842 | 2.0 | fail | 17.0 | 10.0 | NaN | NaN | 3.0 | 3T1 | 7-8yo 32ch | 3mm iso | 0.2 |
| 4 | sub-pixar005 | 4.837782 | 4yo | child | F | R | 0.60 | 0.578947 | 4.0 | inc | 13.0 | 5.0 | NaN | NaN | 2.0 | 3T1 | 7-8yo 32ch | 3mm iso | 0.2 |
Looks like there is a column labeling age. Let’s capture it in a variable
y_age = pheno['Age']
Maybe we should have a look at the distribution of our target variable
import matplotlib.pyplot as plt
import seaborn as sns
sns.distplot(y_age)
<AxesSubplot:xlabel='Age', ylabel='Density'>
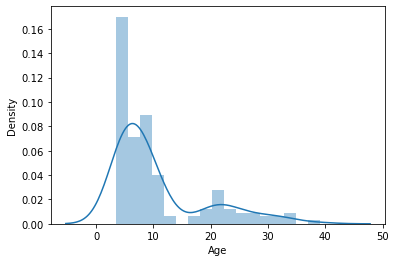
Prepare data for machine learning¶
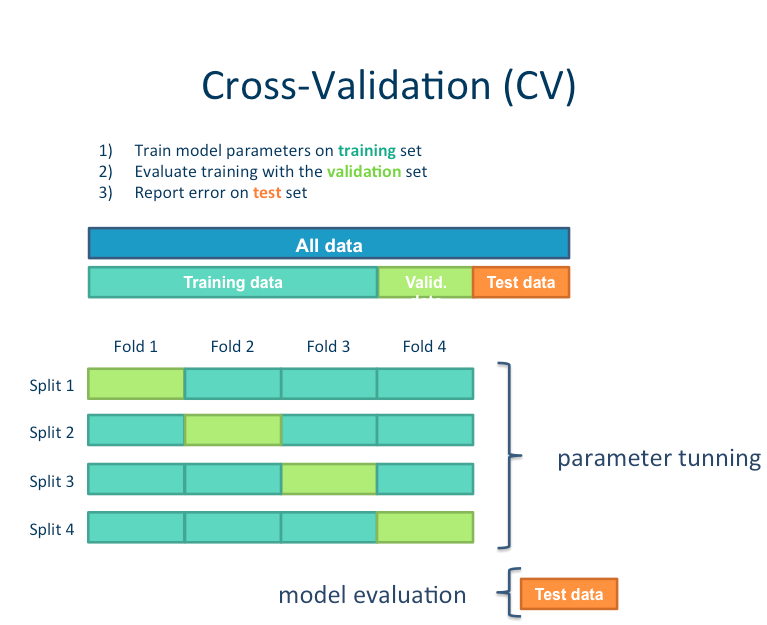
Here, we will define a “training sample” where we can play around with our models. We will also set aside a “validation” sample that we will not touch until the end
We want to be sure that our training and test sample are matched! We can do that with a “stratified split”. This dataset has a variable indicating AgeGroup. We can use that to make sure our training and testing sets are balanced!
age_class = pheno['AgeGroup']
age_class.value_counts()
5yo 34
8-12yo 34
Adult 33
7yo 23
3yo 17
4yo 14
Name: AgeGroup, dtype: int64
from sklearn.model_selection import train_test_split
# Split the sample to training/validation with a 60/40 ratio, and
# stratify by age class, and also shuffle the data.
X_train, X_val, y_train, y_val = train_test_split(
X_features, # x
y_age, # y
test_size = 0.4, # 60%/40% split
shuffle = True, # shuffle dataset
# before splitting
stratify = age_class, # keep
# distribution
# of ageclass
# consistent
# betw. train
# & test sets.
random_state = 123 # same shuffle each
# time
)
# print the size of our training and test groups
print('training:', len(X_train),
'testing:', len(X_val))
training: 93 testing: 62
Let’s visualize the distributions to be sure they are matched
sns.distplot(y_train)
sns.distplot(y_val)
<AxesSubplot:xlabel='Age', ylabel='Density'>
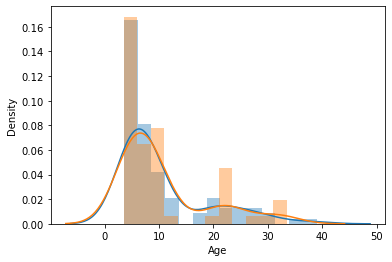
Run your first model!¶
Machine learning can get pretty fancy pretty quickly. We’ll start with a fairly standard regression model called a Support Vector Regressor (SVR).
While this may seem unambitious, simple models can be very robust. And we probably don’t have enough data to create more complex models (but we can try later).
For more information, see this excellent resource: https://hal.inria.fr/hal-01824205
Let’s fit our first model!
from sklearn.svm import SVR
l_svr = SVR(kernel='linear') # define the model
l_svr.fit(X_train, y_train) # fit the model
SVR(C=1.0, cache_size=200, coef0=0.0, degree=3, epsilon=0.1,
gamma='auto_deprecated', kernel='linear', max_iter=-1, shrinking=True,
tol=0.001, verbose=False)
Well… that was easy. Let’s see how well the model learned the data!
# predict the training data based on the model
y_pred = l_svr.predict(X_train)
# caluclate the model accuracy
acc = l_svr.score(X_train, y_train)
Let’s view our results and plot them all at once!
# print results
print('accuracy (R2)', acc)
sns.regplot(y_pred,y_train)
plt.xlabel('Predicted Age')
accuracy (R2) 0.9998487306619585
Text(0.5, 0, 'Predicted Age')
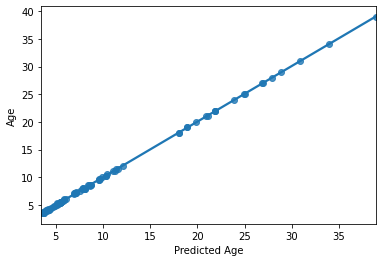
HOLY COW! Machine learning is amazing!!! Almost a perfect fit!
…which means there’s something wrong. What’s the problem here?
from sklearn.model_selection import train_test_split
# Split the sample to training/test with a 75/25 ratio, and
# stratify by age class, and also shuffle the data.
age_class2 = pheno.loc[y_train.index,'AgeGroup']
X_train2, X_test, y_train2, y_test = train_test_split(
X_train, # x
y_train, # y
test_size = 0.25, # 75%/25% split
shuffle = True, # shuffle dataset
# before splitting
stratify = age_class2, # keep
# distribution
# of ageclass
# consistent
# betw. train
# & test sets.
random_state = 123 # same shuffle each
# time
)
# print the size of our training and test groups
print('training:', len(X_train2),
'testing:', len(X_test))
training: 69 testing: 24
from sklearn.metrics import mean_absolute_error
# fit model just to training data
l_svr.fit(X_train2,y_train2)
# predict the *test* data based on the model trained on X_train2
y_pred = l_svr.predict(X_test)
# caluclate the model accuracy
acc = l_svr.score(X_test, y_test)
mae = mean_absolute_error(y_true=y_test,y_pred=y_pred)
# print results
print('accuracy (R2) = ', acc)
print('MAE = ',mae)
sns.regplot(y_pred,y_test)
plt.xlabel('Predicted Age')
accuracy (R2) = 0.6396083549043661
MAE = 3.374176467669733
Text(0.5, 0, 'Predicted Age')
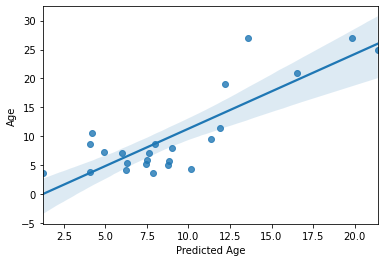
Not perfect, but as predicting with unseen data goes, not too bad! Especially with a training sample of “only” 69 subjects. But we can do better!
For example, we can increase the size our training set while simultaneously reducing bias by instead using 10-fold cross-validation
from sklearn.model_selection import cross_val_predict, cross_val_score
# predict
y_pred = cross_val_predict(l_svr, X_train, y_train, cv=10)
# scores
acc = cross_val_score(l_svr, X_train, y_train, cv=10)
mae = cross_val_score(l_svr, X_train, y_train, cv=10, scoring='neg_mean_absolute_error')
We can look at the accuracy of the predictions for each fold of the cross-validation
for i in range(10):
print('Fold {} -- Acc = {}, MAE = {}'.format(i, acc[i],-mae[i]))
Fold 0 -- Acc = -2.1710326318642017, MAE = 3.187954704036604
Fold 1 -- Acc = 0.46422441845595575, MAE = 3.619571181028147
Fold 2 -- Acc = 0.6399948303961813, MAE = 3.778772442673516
Fold 3 -- Acc = 0.6066444423682056, MAE = 2.46054657698914
Fold 4 -- Acc = 0.6849378233810562, MAE = 4.587586890611935
Fold 5 -- Acc = 0.7897689009120705, MAE = 3.330897879156908
Fold 6 -- Acc = 0.4609127863139971, MAE = 4.8760145676682285
Fold 7 -- Acc = 0.8931286818816472, MAE = 1.86015205627809
Fold 8 -- Acc = -3.8846819551378027, MAE = 3.322838594398261
Fold 9 -- Acc = 0.8326116439043465, MAE = 2.207953719590189
We can also look at the overall accuracy of the model
from sklearn.metrics import r2_score
overall_acc = r2_score(y_train, y_pred)
overall_mae = mean_absolute_error(y_train,y_pred)
print('R2:',overall_acc)
print('MAE:',overall_mae)
sns.regplot(y_pred, y_train)
plt.xlabel('Predicted Age')
R2: 0.6444255239471088
MAE: 3.3298590950496494
Text(0.5, 0, 'Predicted Age')
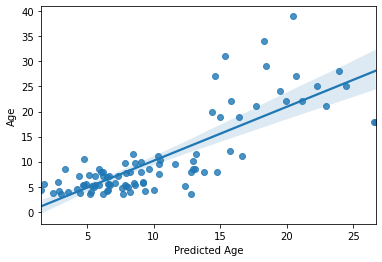
Not too bad at all! But more importantly, this is a more accurate estimation of our model’s predictive efficacy. Our sample size is larger and this is based on several rounds of prediction of unseen data.
For example, we can now see that the effect is being driven by the model’s successful parsing of adults vs. children, but is not performing so well within the adult or children group. This was not evident during our previous iteration of the model
Tweak your model¶
It’s very important to learn when and where its appropriate to “tweak” your model.
Since we have done all of the previous analysis in our training data, it’s fine to try out different models. But we absolutely cannot “test” it on our left out data. If we do, we are in great danger of overfitting.
It is not uncommon to try other models, or tweak hyperparameters. In this case, due to our relatively small sample size, we are probably not powered sufficiently to do so, and we would once again risk overfitting. However, for the sake of demonstration, we will do some tweaking.
We will try a few different examples:
Normalizing our target data
Tweaking our hyperparameters
Trying a more complicated model
Feature selection
Normalize the target data¶
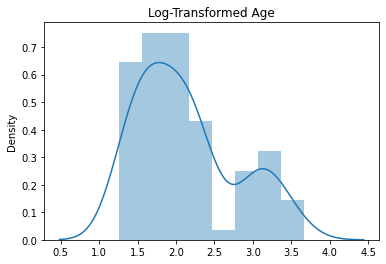
# Create a log transformer function and log transform Y (age)
from sklearn.preprocessing import FunctionTransformer
log_transformer = FunctionTransformer(func = np.log, validate=True)
log_transformer.fit(y_train.values.reshape(-1,1))
y_train_log = log_transformer.transform(y_train.values.reshape(-1,1))[:,0]
sns.distplot(y_train_log)
plt.title("Log-Transformed Age")
Text(0.5, 1.0, 'Log-Transformed Age')
Now let’s go ahead and cross-validate our model once again with this new log-transformed target
# predict
y_pred = cross_val_predict(l_svr, X_train, y_train_log, cv=10)
# scores
acc = r2_score(y_train_log, y_pred)
mae = mean_absolute_error(y_train_log,y_pred)
print('R2:',acc)
print('MAE:',mae)
sns.regplot(y_pred, y_train_log)
plt.xlabel('Predicted Log Age')
plt.ylabel('Log Age')
R2: 0.7196930339633443
MAE: 0.2725545695042319
Text(0, 0.5, 'Log Age')
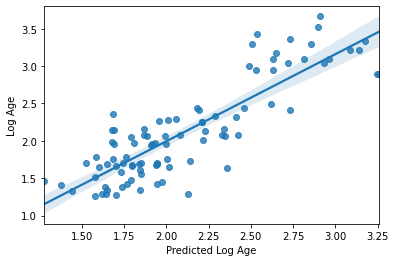
Seems like a definite improvement, right? I think we can agree on that.
But we can’t forget about interpretability? The MAE is much less interpretable now.
Tweak the hyperparameters¶
Many machine learning algorithms have hyperparameters that can be “tuned” to optimize model fitting. Careful parameter tuning can really improve a model, but haphazard tuning will often lead to overfitting.
Our SVR model has multiple hyperparameters. Let’s explore some approaches for tuning them
SVR?
One way is to plot a “Validation Curve” – this will let us view changes in training and validation accuracy of a model as we shift its hyperparameters. We can do this easily with sklearn.
from sklearn.model_selection import validation_curve
C_range = 10. ** np.arange(-3, 8) # A range of different values for C
train_scores, valid_scores = validation_curve(l_svr, X_train, y_train_log,
param_name= "C",
param_range = C_range,
cv=10)
# A bit of pandas magic to prepare the data for a seaborn plot
tScores = pandas.DataFrame(train_scores).stack().reset_index()
tScores.columns = ['C','Fold','Score']
tScores.loc[:,'Type'] = ['Train' for x in range(len(tScores))]
vScores = pandas.DataFrame(valid_scores).stack().reset_index()
vScores.columns = ['C','Fold','Score']
vScores.loc[:,'Type'] = ['Validate' for x in range(len(vScores))]
ValCurves = pandas.concat([tScores,vScores]).reset_index(drop=True)
ValCurves.head()
| C | Fold | Score | Type | |
|---|---|---|---|---|
| 0 | 0 | 0 | 0.341791 | Train |
| 1 | 0 | 1 | 0.321709 | Train |
| 2 | 0 | 2 | 0.329832 | Train |
| 3 | 0 | 3 | 0.322220 | Train |
| 4 | 0 | 4 | 0.336175 | Train |
# And plot!
# g = sns.lineplot(x='C', y='Score',hue='Type',data=ValCurves)
# g.set_xticks(range(11))
# g.set_xticklabels(C_range, rotation=90);
g = sns.factorplot(x='C',y='Score',hue='Type',data=ValCurves)
plt.xticks(range(11))
g.set_xticklabels(C_range, rotation=90);
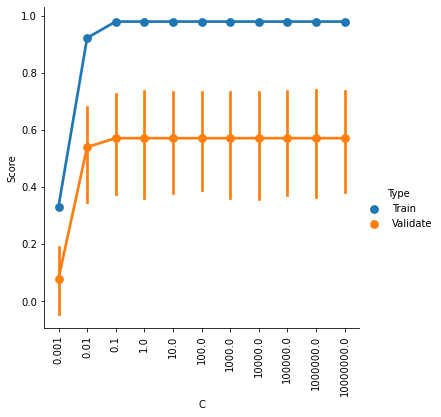
It looks like accuracy is better for higher values of C, and plateaus somewhere between 0.1 and 1. The default setting is C=1, so it looks like we can’t really improve by changing C.
But our SVR model actually has two hyperparameters, C and epsilon. Perhaps there is an optimal combination of settings for these two parameters.
We can explore that somewhat quickly with a grid search, which is once again easily achieved with sklearn. Because we are fitting the model multiple times witih cross-validation, this will take some time
from sklearn.model_selection import GridSearchCV
C_range = 10. ** np.arange(-3, 8)
epsilon_range = 10. ** np.arange(-3, 8)
param_grid = dict(epsilon=epsilon_range, C=C_range)
grid = GridSearchCV(l_svr, param_grid=param_grid, cv=10)
grid.fit(X_train, y_train_log)
/opt/miniconda-latest/envs/neuro/lib/python3.7/site-packages/sklearn/model_selection/_search.py:841: DeprecationWarning: The default of the `iid` parameter will change from True to False in version 0.22 and will be removed in 0.24. This will change numeric results when test-set sizes are unequal.
DeprecationWarning)
GridSearchCV(cv=10, error_score='raise-deprecating',
estimator=SVR(C=1.0, cache_size=200, coef0=0.0, degree=3, epsilon=0.1,
gamma='auto_deprecated', kernel='linear', max_iter=-1, shrinking=True,
tol=0.001, verbose=False),
fit_params=None, iid='warn', n_jobs=None,
param_grid={'epsilon': array([1.e-03, 1.e-02, 1.e-01, 1.e+00, 1.e+01, 1.e+02, 1.e+03, 1.e+04,
1.e+05, 1.e+06, 1.e+07]), 'C': array([1.e-03, 1.e-02, 1.e-01, 1.e+00, 1.e+01, 1.e+02, 1.e+03, 1.e+04,
1.e+05, 1.e+06, 1.e+07])},
pre_dispatch='2*n_jobs', refit=True, return_train_score='warn',
scoring=None, verbose=0)
Now that the grid search has completed, let’s find out what was the “best” parameter combination
print(grid.best_params_)
{'C': 0.1, 'epsilon': 0.1}
And if redo our cross-validation with this parameter set?
y_pred = cross_val_predict(SVR(kernel='linear',C=0.10,epsilon=0.10, gamma='auto'),
X_train, y_train_log, cv=10)
# scores
acc = r2_score(y_train_log, y_pred)
mae = mean_absolute_error(y_train_log,y_pred)
print('R2:',acc)
print('MAE:',mae)
sns.regplot(y_pred, y_train_log)
plt.xlabel('Predicted Log Age')
plt.ylabel('Log Age')
R2: 0.7196930339633443
MAE: 0.2725545695042319
Text(0, 0.5, 'Log Age')
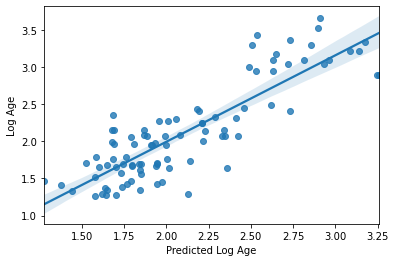
Perhaps unsurprisingly, the model fit is actually exactly the same as what we had with our defaults. There’s a reason they are defaults ;-)
Grid search can be a powerful and useful tool. But can you think of a way that, if not properly utilized, it could lead to overfitting?
You can find a nice set of tutorials with links to very helpful content regarding how to tune hyperparameters and while be aware of over- and under-fitting here:
Trying a more complicated model¶
In principle, there is no real reason to do this. Perhaps one could make an argument for quadratic relationship with age, but we probably don’t have enough subjects to learn a complicated non-linear model. But for the sake of demonstration, we can give it a shot.
We’ll use a validation curve to see the result of our model if, instead of fitting a linear model, we instead try to the fit a 2nd, 3rd, … 8th order polynomial.
from sklearn.model_selection import validation_curve
degree_range = list(range(1,8)) # A range of different values for C
train_scores, valid_scores = validation_curve(SVR(kernel='poly',
gamma='scale'
),
X=X_train, y=y_train_log,
param_name= "degree",
param_range = degree_range,
cv=10)
# A bit of pandas magic to prepare the data for a seaborn plot
tScores = pandas.DataFrame(train_scores).stack().reset_index()
tScores.columns = ['Degree','Fold','Score']
tScores.loc[:,'Type'] = ['Train' for x in range(len(tScores))]
vScores = pandas.DataFrame(valid_scores).stack().reset_index()
vScores.columns = ['Degree','Fold','Score']
vScores.loc[:,'Type'] = ['Validate' for x in range(len(vScores))]
ValCurves = pandas.concat([tScores,vScores]).reset_index(drop=True)
ValCurves.head()
| Degree | Fold | Score | Type | |
|---|---|---|---|---|
| 0 | 0 | 0 | 0.638596 | Train |
| 1 | 0 | 1 | 0.603033 | Train |
| 2 | 0 | 2 | 0.603353 | Train |
| 3 | 0 | 3 | 0.618782 | Train |
| 4 | 0 | 4 | 0.607033 | Train |
# And plot!
# g = sns.lineplot(x='Degree',y='Score',hue='Type',data=ValCurves)
# g.set_xticks(range(7))
# g.set_xticklabels(degree_range, rotation=90)
g = sns.factorplot(x='Degree',y='Score',hue='Type',data=ValCurves)
plt.xticks(range(7))
g.set_xticklabels(degree_range, rotation=90)
<seaborn.axisgrid.FacetGrid at 0x7f5be42b2f50>
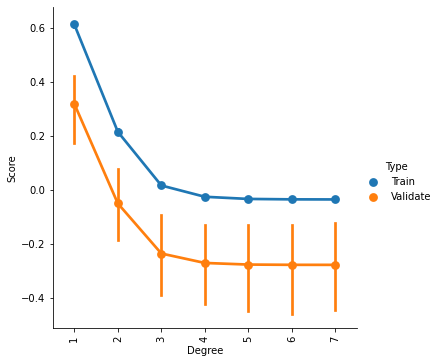
It appears that we cannot improve our model by increasing the complexity of the fit. If one looked only at the training data, one might surmise that a 2nd order fit could be a slightly better model. But that improvement does not generalize to the validation data.
# y_pred = cross_val_predict(SVR(kernel='rbf', gamma='scale'), X_train, y_train_log, cv=10)
# # scores
# acc = r2_score(y_train_log, y_pred)
# mae = mean_absolute_error(y_train_log,y_pred)
# print('R2:',acc)
# print('MAE:',mae)
# sns.regplot(y_pred, y_train_log)
# plt.xlabel('Predicted Log Age')
# plt.ylabel('Log Age')
Feature selection¶
Right now, we have 2016 features. Are all of those really going to contribute to the model stably?
Intuitively, models tend to perform better when there are fewer, more important features than when there are many, less imortant features. The tough part is figuring out which features are useful or important.
Here will quickly try a basic feature seclection strategy
The SelectPercentile() function will select the top X% of features based on univariate tests. This is a way of identifying theoretically more useful features. But remember, significance != prediction!
We are also in danger of overfitting here. For starters, if we want to test this with 10-fold cross-validation, we will need to do a separate feature selection within each fold! That means we’ll need to do the cross-validation manually instead of using cross_val_predict().
from sklearn.feature_selection import SelectPercentile, f_regression
from sklearn.model_selection import KFold
from sklearn.pipeline import Pipeline
# Build a tiny pipeline that does feature selection (top 20% of features),
# and then prediction with our linear svr model.
model = Pipeline([
('feature_selection',SelectPercentile(f_regression,percentile=20)),
('prediction', l_svr)
])
y_pred = [] # a container to catch the predictions from each fold
y_index = [] # just in case, the index for each prediciton
# First we create 10 splits of the data
skf = KFold(n_splits=10, shuffle=True, random_state=123)
# For each split, assemble the train and test samples
for tr_ind, te_ind in skf.split(X_train):
X_tr = X_train[tr_ind]
y_tr = y_train_log[tr_ind]
X_te = X_train[te_ind]
y_index += list(te_ind) # store the index of samples to predict
# and run our pipeline
model.fit(X_tr, y_tr) # fit the data to the model using our mini pipeline
predictions = model.predict(X_te).tolist() # get the predictions for this fold
y_pred += predictions # add them to the list of predictions
Alrighty, let’s see if only using the top 20% of features improves the model at all…
acc = r2_score(y_train_log[y_index], y_pred)
mae = mean_absolute_error(y_train_log[y_index],y_pred)
print('R2:',acc)
print('MAE:',mae)
sns.regplot(np.array(y_pred), y_train_log[y_index])
plt.xlabel('Predicted Log Age')
plt.ylabel('Log Age')
R2: 0.6531506056933571
MAE: 0.29483514511017794
Text(0, 0.5, 'Log Age')
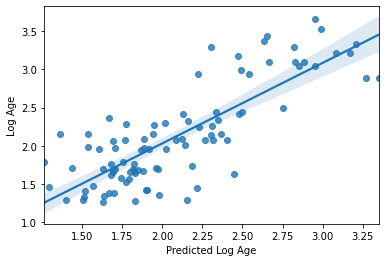
Nope, in fact it got a bit worse. It seems we’re getting “value at the margins” so to speak. This is a very good example of how significance != prediction, as demonstrated in this figure from Bzdok et al., 2018 bioRxiv

See here for an explanation of different feature selection options and how to implement them in sklearn: https://scikit-learn.org/stable/modules/feature_selection.html
And here is a thoughtful tutorial covering feature selection for novel machine learners: https://www.datacamp.com/community/tutorials/feature-selection-python
So there you have it. We’ve tried many different strategies, but most of our “tweaks” haven’t really lead to improvements in the model. This is not always the case, but it is not uncommon. Can you think of some reasons why?
Moving on to our validation data, we probably should just stick to a basic model, though predicting log age might be a good idea!
Can our model predict age in completely un-seen data?¶
Now that we’ve fit a model we think has possibly learned how to decode age based on rs-fmri signal, let’s put it to the test. We will train our model on all of the training data, and try to predict the age of the subjects we left out at the beginning of this section.
Because we performed a log transformation on our training data, we will need to transform our testing data using the same information! But that’s easy because we stored our transformation in an object!
# Notice how we use the Scaler that was fit to X_train and apply to X_test,
# rather than creating a new Scaler for X_test
y_val_log = log_transformer.transform(y_val.values.reshape(-1,1))[:,0]
And now for the moment of truth!
No cross-validation needed here. We simply fit the model with the training data and use it to predict the testing data
I’m so nervous. Let’s just do it all in one cell
l_svr.fit(X_train, y_train_log) # fit to training data
y_pred = l_svr.predict(X_val) # classify age class using testing data
acc = l_svr.score(X_val, y_val_log) # get accuracy (r2)
mae = mean_absolute_error(y_val_log, y_pred) # get mae
# print results
print('accuracy (r2) =', acc)
print('mae = ',mae)
# plot results
sns.regplot(y_pred, y_val_log)
plt.xlabel('Predicted Log Age')
plt.ylabel('Log Age')
accuracy (r2) = 0.7885967069149028
mae = 0.20974032537831747
Text(0, 0.5, 'Log Age')
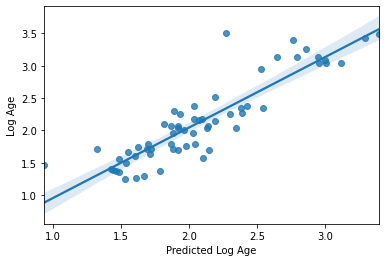
Wow!! Congratulations. You just trained a machine learning model that used real rs-fmri data to predict the age of real humans.
The proper thing to do at this point would be to repeat the train-validation split multiple times. This will ensure the results are not specific to this validation set, and will give you some confidence intervals around your results.
As an assignment, you can give that a try below. Create 10 different splits of the entire dataset, fit the model and get your predictions. Then, plot the range of predictions.
# SPACE FOR YOUR ASSIGNMENT
So, it seems like something in this data does seem to be systematically related to age … but what?
Interpreting model feature importances¶
Interpreting the feature importances of a machine learning model is a real can of worms. This is an area of active research. Unfortunately, it’s hard to trust the feature importance of some models.
You can find a whole tutorial on this subject here: http://gael-varoquaux.info/interpreting_ml_tuto/index.html
For now, we’ll just eschew better judgement and take a look at our feature importances. While we can’t ascribe any biological relevance to the features, it can still be helpful to know what the model is using to make its predictions. This is a good way to, for example, establish whether your model is actually learning based on a confound! Could you think of some examples?
We can access the feature importances (weights) used my the model
l_svr.coef_
array([[ 0.00346787, 0.00235745, 0.02988013, ..., 0.02993066,
-0.00614978, 0.00808308]])
lets plot these weights to see their distribution better
plt.bar(range(l_svr.coef_.shape[-1]),l_svr.coef_[0])
plt.title('feature importances')
plt.xlabel('feature')
plt.ylabel('weight')
Text(0, 0.5, 'weight')
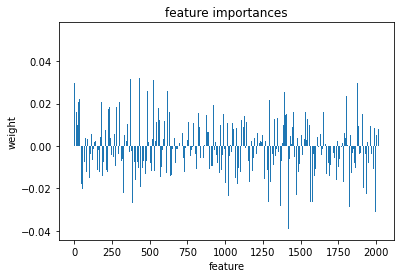
Or perhaps it will be easier to visualize this information as a matrix similar to the one we started with
We can use the correlation measure from before to perform an inverse transform
correlation_measure.inverse_transform(l_svr.coef_).shape
(1, 64, 64)
from nilearn import plotting
feat_exp_matrix = correlation_measure.inverse_transform(l_svr.coef_)[0]
plotting.plot_matrix(feat_exp_matrix, figure=(10, 8),
labels=range(feat_exp_matrix.shape[0]),
reorder=False,
tri='lower')
<matplotlib.image.AxesImage at 0x7f5be07664d0>
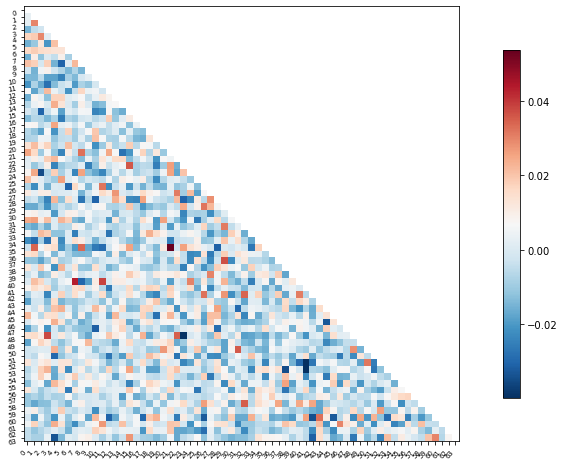
Let’s see if we can throw those features onto an actual brain.
First, we’ll need to gather the coordinates of each ROI of our atlas
coords = plotting.find_parcellation_cut_coords(atlas_filename)
And now we can use our feature matrix and the wonders of nilearn to create a connectome map where each node is an ROI, and each connection is weighted by the importance of the feature to the model
plotting.plot_connectome(feat_exp_matrix, coords, colorbar=True)
<nilearn.plotting.displays.OrthoProjector at 0x7f5bdfc1f8d0>
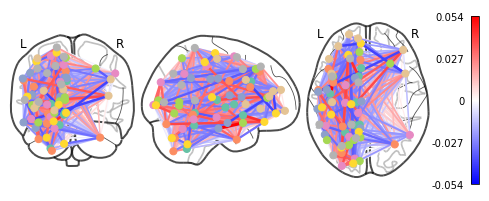
Whoa!! That’s…a lot to process. Maybe let’s threshold the edges so that only the most important connections are visualized
plotting.plot_connectome(feat_exp_matrix, coords, colorbar=True, edge_threshold=0.035)
<nilearn.plotting.displays.OrthoProjector at 0x7f5bda708950>
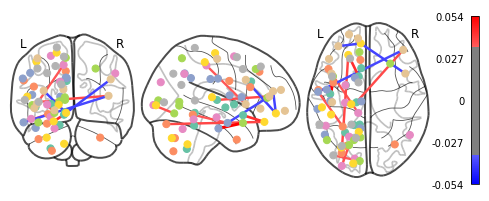
That’s definitely an improvement, but it’s still a bit hard to see what’s going on. Nilearn has a new feature that let’s use view this data interactively!
%matplotlib notebook
plotting.view_connectome(feat_exp_matrix, coords, edge_threshold='98%')